배경
- 모바일 기기 및 엣지 디바이스를 위한 딥 러닝 모델 배포 및 활용 필요성의 급속한 증가
- 최근의 드론, 로봇을 포함하여, 스마트폰 및 다양한 IoT 기기들은 그 컴퓨팅 환경의 특성으로 인해 제한된 연산 능력, 메모리, 전력을 가지고 효율적으로 컴퓨터 비전, 음성 및 자연어 처리 등과 관련한 딥 러닝 모델 탑재 및 추론이 지속적으로 요구되고 있음
- 이를 위해 딥 러닝 알고리즘을 경량화 하여 적은 저장 공간, 연산량을 요구하면서 고속으로 추론할 수 있는 기술을 필요로 함
- 이에 따라 딥 러닝 모델의 경량화 및 추론에서의 효율성에 관한 관심이 점차 증가하고 있음
딥러닝 모델 경량화란?
딥뉴럴 네트워크에서 방대한 연산량을 줄이기 위한 연구.
경량화를 하는 이유는 real-time에서 작동하지 않기 때문에 latency를 빠르게 하기 위해서, 메모리를 많이 차지 하기 때문에 memory를 줄여서 특정 환경에서 실행하기 위해, 하드웨어 디바이스 중에는 8비트만 지원하기 때문에 평소에 사용하던 32비트를 8비트로 변환하기 위해서 등이 있습니다.
GPU 뿐만 아니라 모바일, 엣지 디바이스, 클라우드 등에 딥러닝 모델이 쓰이기 위해서 연구되고있다.
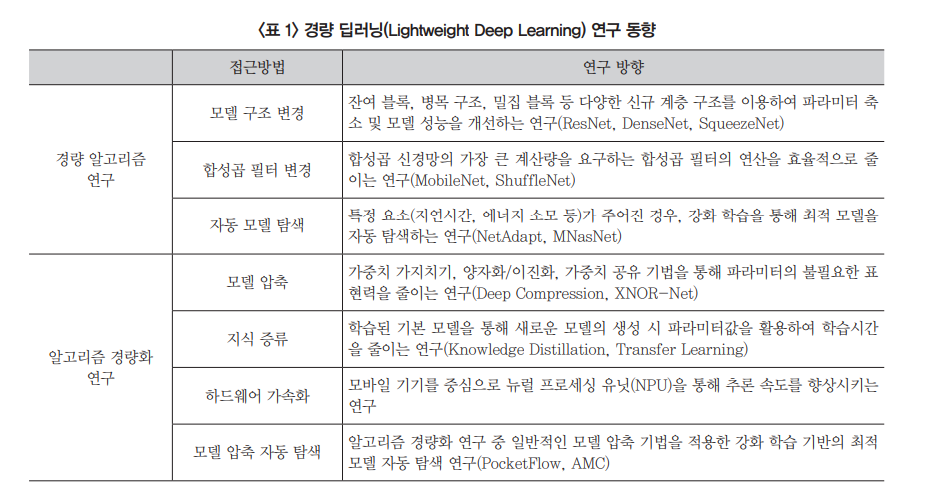
딥러닝 경량화 방향
딥러닝 경량화에 대한 연구는 알고리즘 자체를 적은 연산과 효율적인 구조로 설계해서 기존 모델 대비 효율을 극대화하는 ‘경랑 딥러닝 알고리즘 연구’와, 이미 만들어진 모델의 파라미터를 줄이는 ‘모델 압축’ 기법으로 나눌 수 있다.
- 경랑 딥러닝 알고리즘 => 새로운 알고리즘을 만듦
- 모델 압축(알고리즘 경량화) => 기존의 알고리즘을 경량화 시킴
<ETRI 경량 딥러닝 기술 동향>