https://arxiv.org/pdf/2201.09792.pdf
Abstract
- Vision task에서 CNN모델이 수년동안 주류였지만, 최근에 transformer based model(ViT)이 CNN의 성능을 뛰어넘고있다.
- ViT의 높은 성능은 transformer architecture때문일까? 아니면 patch embedding때문일까?
- 이 논문은 후자에 대한 증거를 제시한다.
- 여기서 제안하는 ConvMixer은 patch를 input으로 받고, network내에서 동일한 size, resolution을 유지하며, spatial, channel dimension을 separate한다.
- Mixing step에서 CNN만을 사용
- 비슷한 파라미터 수, 데이터셋에서 Convmixer은 resnet, ViT, MLP-Mixer보다 더 좋은 성능을 보였다.
Introduction
- CNN이 수년동안 computer vision task에서 지배적인 아키텍쳐였지만 최근에 Vision transformer 아키텍쳐가 고전적인 CNN을 뛰어넘는 성능을 보여주고있다.(특히 큰 데이터 셋에서)
- NLP에서 처럼 Vision task에서도 transformer based architecture가 주류가 되는 것은 시간 문제처럼 보이지만, NLP와는 달리 vision task에서는 이미지를 입력으로 넣을때 representation 변화가 필요하다.
- Attention layer의 time complexity는 O(N^2)으로 이미지를 pixel로 그대로 넣으면 연산량이 너무 커서, patch 단위로 나눈 후 linearly embedding해 입력으로 넣어야한다.
- 이번 연구에서, 우리는 근본적으로 Vision transformer의 강력한 성능이 transformer architecture 보다는 patch based representation에서 나오는 것인지 확인해보고자한다.
- MLP-Mixer와 비슷한 간단한 CNN 기반의 ConvMixer을 개발한다.
- patches representation
- 모든 layer에서 equal resolution and size representation 유지
- does no downsampling of the representation at successive layers
- channel-mixing, spatial-mixing
- Vit, MLP-mixer와는 다르게 standard convolution만을 사용
- ConvMixer은 성능이나 속도를 maximize하기 위한 모델 디자인은 아니며, patch representation 자체가 ViT, MLP-Mixer등 모델의 성능에 영향을 미치는 중요한 요인이라는 것을 제시하는 모델
- 다른 요소들로부터 patch embedding의 효과를 정확하게 구별하기 위해서는 더 많은 실험이 필요하지만, 우리는 이 ConvMixer가 미래에 더 advaned architectures들과 비교할 수 있는 강력한 convolutional-but-patch-based baseline 될거라 믿는다.
A Simple Model : ConvMixer
- ConvMixer은 patch embedding layer 이어 단순 반복되는 convolutional block으로 구성된 구조
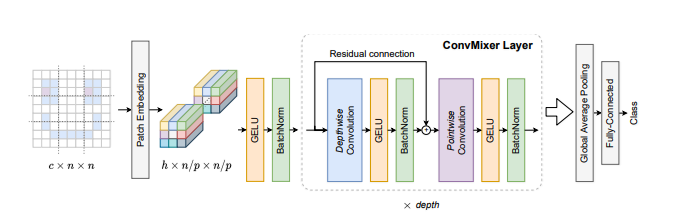
1. (Patch Embedding) image를 patches로 나눈다
- Patch size P와 embedding 차원 h를 가진 패치 임베딩은 입력 채널, 출력 채널 h, kernel size P, stride P를 가진 컨볼루션으로 구현
2. (ConvMixer Layer)
- depth번 만큼, Depthwise Convolution(residual connection) + Pointwise Convolution을 반복
- Depthwise Convolution은 spatial location의 mix(공간 방향의 convolution 진행), Pointwise Convolution은 channel location의 mix를 하기 위해 시행(채널 방향의 convolution 진행), 중간에 activation + batch norm 넣어줌
3. Global Average Pooling 후 (1,1,h) 벡터를 linear transform해 classifiacation 값을 얻음
EXPERIMENTS
- Training step
- pretraining이나 데이터 추가 없이 ImageNet classification에서 ConvMixer을 평가
- RandomAugment, mixup, Cutmix, random erasing 사용
- AdamW optimizer, simple triangul learning rate schedule 사용
- 컴퓨팅 파워때문에 하이퍼파라미터 튜닝을 하지 못했고, competitors보다 적은 에폭으로 학습
- ConvMIxer은 아직 성능 향상의 여지가 많음.
- Results
- ConvMixer-1536/20 with 52M parameters은 imagenet에서 81.4% 정확도 기록
- ConvMixer-768/42 with 21M parameters은 80.2% 기록
- 더 큰 kernel size에서 더 작은 patch size에서 높은 성능을 보임
- ConvMixer-1536/20 patch size를 7에서 14로 늘렸을때 정확도는 78.9%기록했지만, 속도는 4배 빨라짐
- Comparisons
- Parameter 수를 비슷하게 해서 훈련시켰을 때, DeiT와 ResMLP는 ConvMixer와 다르게 hyperparameter tuning이 되어 있음에도(특히 ResNet은 tuning하는데 지금까지 엄청난 자원이 소모되었음에도), epoch도 2배임에도 ConvMixer을 0.2%밖에 outperform하지 못했다.
- 하지만 ConvMixer은 patch size가 더 작기 때문에 다른 모델들에 비해 inference 속도가 느리다. 하이퍼파라미터 튜닝과 최적화를 통해 이 gap을 줄일수있다.
RELATED WORK
- Isotropic architectures
- Vision transformer은 첫번째 layer에 patch embedding을 사용하고, 네트워크 전체에서 똑같은 size와 shape 가진 "isotropic"아키텍처의 패러다임을 열었다.
- 이러한 모델은 반복되는 transformer-encoder blocks과 유사하고, self attention과 MLP를 대체하는 다른 operation이 있다.