Auto Encoder란입력 데이터를 압축시켜 압축시킨 데이터로 축소한 후 다시 확장하여 결과 데이터를 입력 데이터와 동일하도록 만드는 일종의 딥 뉴럴 네트워크 모델이다. Auto Encoder는 입력 데이터를 일종의 Label(정답)로 삼아 학습하므로Self-supervised Learning이라고 부르기도 하지만 어쨋거나 y값이 존재하지 않으며 이용하지 않는다는 점에서Unsupervised Learning으로 분류되는 모델
AutoEncoder 구조
오토인코더는 위의 그림에서 볼 수 있듯이 항상 인코더(encoder)와 디코더(decoder), 두 부분으로 구성되어 있다.
인코더(encoder) : 인지 네트워크(recognition network)라고도 하며, 입력을 압축한다.
디코더(decoder) : 생성 네트워크(generative nework)라고도 하며, 압축된 표현을 다시 입력으로 복원한다.
수식
Input data를 encoder network에 통과시켜 압축된 z(latent space)값을 얻는다.
압축된 z vector로부터 Input Data와 같은 크기의 출력 값을 생성한다.
이때 Loss값은 입력값x와 Decoder를 통과한 y값의 차이이다.
학습방법
Decoder Network를 통과한 output layer의 출력 값은 input값의 크기와 같아야 한다.
학습을 위해서 출력값과 입력값이 같아져야 한다.
다시 말해, 입력데이터를 압출시켜 압축 시킨 데이터로 축소한 후에 다시 확장하여 결과 데이터를 입력 데이터와 동일하도록 만드는 과정이며, Unsupervised Learning으로 분류된다. 이때 압출시키는 부분은 Encoder라고 하며, 확장시키는 부분은 Decoder라고 한다.
오토인코더에서는 필연적으로 정보의 손실이 일어나지만 이는 중요한 정보만 남겨두는 일종의 데이터 가공이라고 볼 수 있습니다. 이런 특징으로 인해 오토인코더는 주로 복잡한 비선형 데이터의 차원을 줄이는 용도로 쓰인다.
Stacked Auto Encoder
AutoEncoder는 보통 Stacked Auto Encoder구조로 많이 활용되며, 대칭적 구조이다.
input layer의 입력데이터를 압축시켜 가장 대표적인 특성을 추출하 층이 Encoded Layer에 있는 노드들이다. 이 층이 압축된 데이터를 갖고 있는 layer이며, 결과 데이터가 입력 데이터와 얼마나 동일하게 출력할 것인가를 결정하는 역할이다.
AutoEncoder 응용 분야
오토인코더의 주요 응용 분야는 차원축소, 이상 감지(anomaly detection) 또는 이미지 노이즈 제거(image denoising)이다. 오토인코더의 작업이 매니폴드 즉 주어진 데이터 매니폴드에 있는 데이터를 재건하는 것임을 알고 있고, 오토인코더가 해당 매니폴드 안에 존재하는 입력만 재건할 수 있기를 원한다. 따라서 우리는 모델이 훈련 중에 관찰한 것들만을 재건할 수 있도록 제한하고, 따라서 새로운 입력에 존재하는 어떠한 변화(variation)도 제거되는데, 왜냐하면 이 모델은 이러한 미세한 변화perturbations에 영향을 받지 않을 insensitive 것이기 때문이다.
- 현재의 딥러닝은 수 많은 데이터에 의존하고 있음. 데이터가 없으면, 성능이 나오지 않는 것이 현실
- 딥러닝의 성능이 좋아서 각광을 받고 있긴 하지만, 대용량 데이터가 있어야만 성능을 발휘하기 때문에 현재의 딥러닝은 인공지능이라기보다는 고도의 통계처리 기계라고 보는 것이 맞다는 의견도 있음
- 데이터 label이 필요한 지도 학습 task라면 데이터셋 구축이 더 어려움
- 이러한 딥러닝의 데이터 의존성 문제를 해결하기 위한 수많은 연구가 있음
- 대표적인 연구중 하나 Meta-Learning
Meta Learning & Few-shot Learning
- 메타러닝(Meta-Learning) : Learning to learn, 즉 학습을 잘하는 방법을 학습하는 것에 대한 연구분야
- Few shot Learning : 적은 데이터만을 가지고 좋은 성능를 뽑아내기 위한 방법론들을 다루는 연구분야
- 위의 두 분야는 분명 다른 분야지만, 결국 목표는 '처음 마주하는 데이터(적은 데이터)에 대한일반화성능 확보'이기에 서로 밀접하게 연관되어 있음. - 일반화, 혹은보편화를 더더욱 추구하는 연구 분야이기 때문에 미래 우리가 나아가야 할범용 인공지능(Artificial generel Intelligence)를 위한 초석.
사실 처음 마주하는 데이터에 대한일반화 성능 확보는 모든 딥러닝 연구의 목표라고 봐도 무방합니다.
Meta Learning & Transfer Learning
- Transfer Learning과 Meta Learning 둘 다 Few show Learning을 위해 제안된 알고리즘
- Transfer Learning은 조금 더 Pretrained 모델을 기반으로 적은 Dataset을 기반으로, Fine-Tuning하는 알고리즘이라는 점에 초점
- Meta Learning은 말 그래도 'Learning to learn'이라는 concept처럼, hand-design의 느낌이 나는 transfer learning보다 빠르게 적응할 수 있는 최적의 알고리즘을 찾기 위해 제안
- Meta Learning이 더 적은 Dataset을 target하여, 빠르게 최적화가 이루어질 수 있도록, 일반화에 포커싱 되어있는 방식
용어들 한줄 정리
Meta Learnin
Learning to learn. 즉, 기존 training time에 접해보지 않은 문제들을 빠르고/능숙하게 학습하도록 학습하는 것.
Transfer Learning
특정 태스크 (Upstream task)를 학습한 모델의 일부를 다른 태스크 (Downstream task) 수행에 전이하여 재사용하는 기법.
Few shot Learning
Transfer Learning의 일종으로, Downstream task에서 데이터를 few samples(몇개)만 사용하는 것
One shot Learning
Transfer Learning의 일종으로, Downstream task에서 데이터를 한개만 사용하는 것
Zero shot Learning
Transfer Learning의 일종으로, Downstream task의 데이터를 사용하지 않고 수행하는 것
Finetuning
기존의 모델을 새로운 데이터에 low learning rate으로 재학습 시키는 것 (freeze 여부는 상황에 따라 다름)
파라미터를 계속 바꿔가면서 더 좋은 모델을 만들때는,모델과 파라미터의 버전을 어느순간 일치시키기 힘들어진다.(파라미터를 바꿀 때 마다 메모해 놓는것도 귀찮고, 사람이 개입하기 때문에 실수가 발생할 우려도 있다. 무엇보다, 과거 모델과 현재 모델을 비교하는 A/B 테스트를 하려면, 과거 학습시에 썼던 파라미터가 보존되어 있어야한다. 실험할 때마다Jupyter notebook을 카피해 놓을 자신이 있는가?)
PyTorch Project Template Overview
OOP(객체지향프로그래밍) + 모듈 -> 프로젝트 // 코드도 레고처럼
다양한 프로젝트 템플릿이 존재
사용자 필요에 따라 수정하여 사용
실행, 데이터, 모델, 설정, 로깅, 지표, 유틸리티 등 다양한 모듈들을 분리하여 프로젝트 템플릿화
프로젝트마다 공통된 워크플로우는 각자 사정에 맞게 설계를 해 두면 편하기도 할 뿐더러, 모델의 관리도 쉬워지고, 프로젝트를 성공적으로 마칠수도 있을 것이다. 더 많은 머신러닝, 딥러닝 프로젝트를 이 템플릿에 담아보면서, 조금씩 수정해 나가면 개발자와의 협업도 수월해 질 것으로 생각한다.
: 기존의 모델은 하나의 단어를 위해 이전의 유닛들을 모두 처리해야한다는 단점이 있었다. 그로 인해 Input이 길어지면 모델은 엄청 복잡해지며, RNN은 특히 vanishing gradient 문제를 해결하기가 매우 어려운 단점이 있었다.
: Sequential model인 RNN과 달리 CNN은 여러 개를 평행하게 처리한다. 각각의 장점을 섞은 것이 Transformer model이다.
Self-Attention
: 문맥별로 '아프리카'라는 단어의 의미는 달라진다.이를 고려하는 것이 self-attention이다.
- 각 단어마다 Query, Key, Value값이 존재.
- Q는 질문을 담당한다. ex. Q^<3> = what's happening there? 이 예시에서는 행동을 의미하는 x^<2>의 키값(k^<2>)이 가장 클 것이다.
- q, k 쌍을 해당 단어의 value와 곱한 것이 A가 된다.
=> 아프리카가 고정된 의미를 가지지 않고, visit의 대상으로서의 의미를 지닌다는 것이 self-attention의 핵심이다.
cf. 네모 안의 식은 vectorized implementation이다.
Multi-Head Attention
: 가중치 W가 질문과 답이 이루어지도록 역할을 한다.
- 첫 질문 What's happening은 파란색으로 표현(앞서 K<2>가 Q<3>에 가장 잘 답한다는 점에서 화살표가 굵게 칠해짐)
- 두 번째 질문 when?이 빨간색으로 표현, 파란색 뒤에 쌓아짐.
- 세 번째 질문 Who?는 검정.
- heads는 별개의 질문(feature)을 반영.
- 각각의 head는 영향을 주고받지 않으므로 for문을 통해 평행하게 동시 진행.
=> 최종값은 각각의 head를 W와 곱해서 이루어진다.
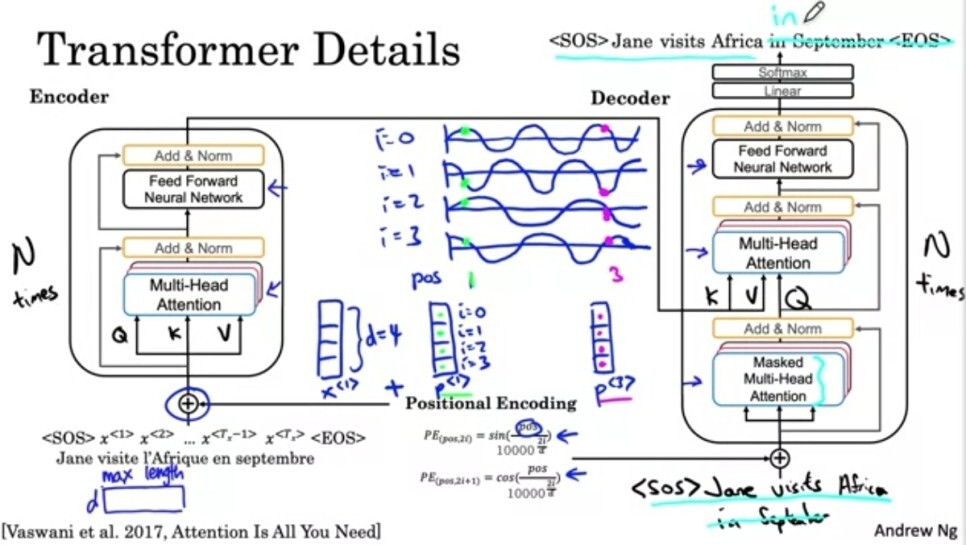
Transformer Network
: 여태 생략했지만, Sequence model에서는 SOS(start of sentence), EOS(end of sentence) 토큰이 유용하다.
- Encoder block은 앞서 배운 Multi-head attention을 이용해 Feed forward neural network에 들어가서 문장의 인상적인 특징들을 뽑아낸다. 이를 N번 반복하는데, 이를 소개한 논문에서는 6번 진행하였다.
- Decoder는 번역문장을 생성해내는데, 하나를 번역할 때마다 다시 Input으로 가져와서 활용한다. 이렇게 가져온 단어로 QKV를 만들어 첫 번째 multi-head Attention을 통과한 뒤 다음 head를 위한 Q만 가져온다(번역본의 문장 정보를 반영). 이 때 K와 V는 Encoder의 output에서 가져온다.(이는 프랑스어 원본 문장의 정보를 반영). 마찬가지로 Feed forward를 N번 진행하여 번역된 단어를 하나씩 산출해낸다.
- Self attention은 단어의 위치정보를 활용하지 않는다. Positional Encoding은 sin/cos함수를 통해 단어의 위치를 산출해낸다. 이는 word embedding vector에 대응하는 동일한 차원의 positional embedding vector을 활용한다. 해당 식에서 pos는 단어의 위치, i는 벡터의 각각행, d는 차원을 의미한다. 짝수(0포함)는 sin, 홀수는 대응하는 cosine 함수를 활용. positional vector의 값은 sin/cos값들로 채워진다. positional encoding은 encoder에 input으로 들어간다. 이들이 하는 것은 ResNet의 residual block과 같은 역할을 한다.
- Add & Norm은 Batch norm의 역할을 수행한다.
- Masked multi-Head attention은 training에만 사용된다. training은 완벽하게 번역된 결과물을 가지기 때문에, 문장의 뒷부분 정답을 가려서 지금까지 모델이 잘 했는지를 평가하는 데에 활용된다.
이번 강의부터는 Sequence-to-sequence 모델에 대해서 배우게 된다. Basic model부터 시작해서 Beam search와 attention model에 대해서 알아보자.
'Jane viste l'Afrique en septembre'라는 프랑스어로 된 문장을 영어 문장으로 변환하고 싶다면, 프랑스어로 된 문장 시퀀스를x^{<1>}x<1>부터x^{<5>}x<5>까지 표시하고,y^{<1>}y<1>에서y^{<6>}y<6>까지 사용해서 output 시퀀스 단어를 표시한다.
그렇다면 어떻게 새로운 network를 학습해서 시퀀스 x를 입력으로 하고 시퀀스 y를 출력할 수 있을까?
위와 같은 모델을 통해서 가능한데, 이 모델은 인코더(Encoder) 네트워크와 디코더(Decoder) 네트워크로 구성된다.
인코더 네트워크를 통해서 프랑스어 단어를 입력 받고, 디코더 네트워크를 통해서 영어 단어 하나하나를 출력하게 된다.
이 모델은 충분한 프랑스어 문장과 영어 문장의 데이터셋이 있을 때, 효과가 있다는 것이 밝혀졌다.
이와 비슷한 구조로 Image captioning(이미지 캡션)도 수행할 수 있다.
이 슬라이드에서는 pre-trained된 AlexNet을 사용해서, 마지막 softmax layer를 삭제한 후에 AlexNet으로 4096 차원의 특성 벡터를 출력하게 되는데, 이 부분이 이미지의 인코더 네트워크라고 할 수 있다. 그리고 RNN 모델을 디코더 네트워크로 사용해서 4096차원의 특성벡터를 입력으로 사용해서 이미지를 설명하는 단어들이 출력으로 나오게 된다.
위에서 언급한 두 모델에서 우리는 무작위로 선택된 번역을 원하지 않거나, 가장 정확한 번역을 원할 수 있고, 이미지 캡션 또한, 무작위의 캡션을 원하지 않고, 가장 정확한 캡션을 원할 수 있다.
다음으로 어떻게 정확한 번역이나 캡션을 생성할 수 있는지 알아보도록 하자.
Picking the Most Likely Sentence
Machine translation(기계번역)모델과 강의의 첫 주에 배웠던 language 모델은 몇 가지 비슷한 점과 차이점이 있다.
기계번역은 conditional language model(조건부 언어모델)로 생각할 수 있는데, 아래의 기계번역 모델의 구성을 살펴보면, 뒤쪽의 디코더 네트워크가 language 모델과 유사한 것을 볼 수 있다.
즉, language 모델은 0벡터에서 시작했지만, 기계번역 모델에서는 인코더 네트워크를 통과한 출력이 language 모델로 입력되는 것과 같다.
그리고, 입력으로 프랑스어 문장 x과 출력인 영어 문장 y가 주어진다면, 모델은 입력(프랑스어문장)에 대한 출력(영어문장)의 확률을 알려준다. P(y<1>,⋯,y<Ty>∣x<1>,⋯,x<Tx>)
결국 우리가 위 모델을 통해서 프랑스어 문장을 영어로 번역하려면, 가장 높은 확률의 번역P<1>,⋯,y<Ty>∣x))을 찾아야 한다.
위에서 언급했지만, 모델은 입력인 프랑스어 문장에 대해서 영어 문장들의 조건부 확률을 출력한다.
그래서 모델의 확률 분포를 얻어서 샘플링했을 때, 괜찮은 번역을 얻을 수도 있고, 좋지 않은 번역을 얻을 수도 있다.
그렇기 때문에 좋은 번역을 얻기 위해서 우리는 조건부 확률을 최대로하는 영어 문장을 찾아야 한다.
즉, 기계번역 시스템을 개발할 때, 우리가 해야할 일 중의 하나는 이 조건부 확률을 최대화하는 알고리즘을 고안하는 것이다. 자주 사용되는 알고리즘은 Beam Search인데, 이것은 잠시 후에 알아보자.
Greedy 알고리즘도 있는데, 이 알고리즘은 사용하면 안된다. 이 알고리즘은 첫 번째 단어를 예측할 때, 가장 높은 확률의 단어 하나만 선택한 후에, 가장 높은 확률 두 번째 단어를 선택하고, 그후에 가장 높은 확률의 세 번째 단어를 선택한다.
우리가 원하는 것은 전체 결과 시퀀스의 확률을 최대화하는 것이기 때문에, 가장 높은 단어만을 선택하는 접근 방법은 효과가 없다.
위 예시처럼, 'Jane is'까지 두 단어를 선택한 후에, 세번째 단어를 선택할 때를 살펴보자.
Jane is 다음에는 going이라는 단어가 더 흔하게 사용되기 때문에 greedy 알고리즘으로는 going이 선택될 확률이 높다. 하지만, 전체 결과를 보다시피, going을 선택한 문장은 잘못된 번역이라는 것을 확인할 수 있다. 이처럼 가장 높은 확률의 단어만을 찾아가는 접근법은 효과가 없다는 것을 볼 수 있다.
따라서, 마지막 단어까지 도달하면서 가장 높은 확률의 문장을 찾아야하는데, voca size를 고려하면 모든 단어들을 평가기는 불가능하다. 따라서heuristics 탐색 알고리즘을 사용해서 대략적인 최대치를 찾는다. 항상 최대 확률의 결과를 보장하지는 않지만, 이정도로 충분할 수 있다.
Beam Search
BeamSearch는 가장 확률이 높은 output을 찾기 위해서 사용되는 알고리즘이다. Greedy 알고리즘은 가장 확률이 높은 단 하나의 단어만을 계속 선택하지만, Beam Search 알고리즘은 다양한 경우를 고려한다.
Beam Search가 어떻게 동작하는지 살펴보자.
먼저 Beam search는 B라는 매개변수를 가지고 있는데, 이것은 Beam width라고 불린다. 여기에서 B=3으로 설정했는데, 이는 beam search가 3개의 가장 높은 가능성을 고려한다는 것을 의미한다.
그래서 Step 1에서 가장 확률(P(y^{<1>}|x)P(y<1>∣x))이 높은 단어 3개 'in', 'jane', 'september'를 선택하게 된다.
Step 2에서는 두 번째에 위치하는 단어를 예측하는데, Step 1에서 선택된 3개의 단어의 조건부 확률을 구한다. 즉, Step 1에서 선택한 3개의 단어를 Step 2의 입력으로 사용해서 가장 높은 확률(P(y^{<1>}, y^{<2>}|x) = P(y^{<1>}|x)P(y^{<2>}|x, y^{<1>})P(y<1>,y<2>∣x)=P(y<1>∣x)P(y<2>∣x,y<1>))을 가지는 3개의 출력을 다시 선택하게 되는 것이다.
결과적으로 'in September', 'jane is', 'jane visits'가 선택되었다고 하자.
Step 3도 동일하게 진행하고, 가장 높은 가능성을 가진 3개의 확률을 선택하게 된다. 이렇게 계속 진행하다가 <EOS>를 만나게 되면, 종료하게 되고 영어 문장을 출력하게 된다.
위 과정은 B=3일 때의 탐색 과정을 살펴본 것이고, 만약 B=1이라면 Greedy 알고리즘과 동일하게 된다.
다음으로 Beam search를 더욱 극대화할 수 있는 몇 가지 팁에 대해서 알아보자.
Refinements to Beam Search
Beam Search는 위와 같이 결국에는 조건부 확률의 최대가 되는 경우를 찾는 것이다. 그리고 조건부 확률을 풀어서 쓰면 다음과 같다.
P는 확률이기 때문에 모든 값이 1보다 작고, 결국 P를 곱하다 보면 그 값은 1보다 훨씬 작아지게 된다. 특히나, 단어가 많을 수록 그 값은 기하급수적으로 작아지며, 컴퓨터가 그 값을 정확하게 표현(저장)하기에는 너무 작아질 수도 있다.
또한 1보다 너무 작아지게 되면, 모델이 짧은 번역을 더 선호하게 되는 문제가 발생할 수도 있다.(short output 선호)
이런 문제점을 방지하기 위해서 확률에 log를 취해서 최대가 되는 값을 찾는다.
log함수도 마찬가지로 증가하는 함수이기 때문에logP(y|x)logP(y∣x)를 최대화하는 것은 P(y|x)를 최대화하는 것과 동일하며, 이렇게 log를 취해주게 되면 수치적으로 더 안정적이게 된다.
그런데, 이 경우에도 확률은 항상 1보다 작거나 같기 때문에, 더 많은 단어가 있을수록 음수가 점점 커지게 된다.
그래서 알고리즘이 더욱 잘 동작하도록하는 방법이 있는데, 그 방법은 단어의 수T_yTy로 normalization하는 것이다.
또한,T_yTy가 너무 큰 경우의 페널티를 감소시키기 위해서\alphaα승을 사용할 수도 있는데, 위 방법은 이론적인 근거가 딱히 존재하지는 않지만, 경험과 실험을 통해서 효과가 있다는 것을 발견했다.
(위 방법을 normalized log propability라고 부르기도 한다.)
마지막으로 Beam width B에 대해서 이야기해보자.
B의 크기는 어떻게 선택해야 할까?
만약 B의 크기가 아주 크다면, 많은 가능성들 고려하게 되고, 따라서 더 좋은 결과를 얻는 경향이 있다. 하지만, 더 느려지고 메모리도 많이 차지하게 된다.
반면, B의 크기가 매우 작다면, 고려하는 경우의 수가 적기 때문에 대체로 좋지 않은 결과를 얻게 되지만, 속도는 더 빠르고 메모리 또한 덜 차지하게 된다.
예시는 3개의 가능성을 살펴보았지만(B=3), 실제 시스템에서는 10개를 사용하기도 하고, 최고의 결과를 위해서 1000~3000개를 사용하기도 한다.
그리고 BFS나 DFS와 같은 탐색 알고리즘과 다르게, Beam 탐색은 훨씬 더 빠른 알고리즘이다. 하지만, 정확한 최대값을 보장하지는 않는다는 것을 기억하자.
Error Analysis in Beam Search
Beam Search는 휴리스틱 탐색 알고리즘이며, 항상 best 확률의 문장을 출력하지는 않는다.
이때, 만약 Beam Search에서 mistake가 있으면 어떻게 해야할까?
이번에는 Error analysis를 통해서, beam search에 문제가 있는지 확인할 수 있는 방법에 대해서 알아보자.
프랑스어 문장을 예시로, 아래에 인간이 번역한 것(y^\stary⋆)과 알고리즘 모델이 번역한 결과물(\hat{y}y^)이 있다.
여기에서 유용한 방법은 모델을 사용해서P(y^\star |x)P(y⋆∣x)와P(\hat{y}|x)P(y^∣x)를 계산하는 것이다. 그리고 둘 중의 어느 값이 더 큰 지 확인한다.
이렇게 두 값을 비교하는 것으로 모델의 오류(RNN의 문제인지, Beam Search의 문제인지)를 명확하게 설명할 수 있다.
만약P(y⋆∣x)가P(y^∣x)보다 더 크다면, Beam Search가 더 높은 확률의 번역을 선택하지 못한 것이므로 Beam Search 알고리즘에 문제가 있다고 판단할 수 있다.
반대로P(y⋆∣x)가 P(y^∣x)보다 작거나 같다면, RNN 모델이 잘못된 번역을 더 높은 확률로 예측했으므로, RNN 모델에 문제가 있다고 판단할 수 있다.
그리고 아래 과정을 통해서 RNN의 모델과 Beam Search 알고리즘에 의한 오류의 수를 파악할 수 있다. 이런 Error analysis process를 통해서 효율적으로 개발의 방향을 설정할 수 있다.
Bleu Score (기계번역 성능 평가 방법)
기계번역(Machine Translation)에서의 challenge 중의 하나는 꽤 괜찮은 번역을 여러 개 만들 수 있다는 것이다.
하나의 정답이 있는 이미지 인식과는 달리 여러가지의 좋은 정답이 있다면 기계번역 시스템은 어떻게 이것들을 평가할 수 있을까?
정확성을 측정하면되는데, 보편적으로 Bleu Score라는 방법이 사용된다.
아래 주어진 프랑스어 문장 'Le chat est sur le tapis'에 대해 괜찮은 번역이 두 개가 있다(Ref1, Ref2).
실제 두 번역은 잘 번역된 것이고, Bleu Score는 번역이 얼마나 괜찮은지 측정하는 점수를 측정할 수 있게 해준다. 만약 모델이 예측한 결과가 사람이 제공한 reference와 가깝다면 Bleu Score는 높게 된다.
Bleu Score는 직관적으로 기계가 생성하는 글의 유형을 최소한 인간이 만들어낸 reference에서 나타나는지 살펴보는 방법이다. 극단적인 기계번역(MT)의 결과를 가지고 어떻게 점수가 계산되는지 살펴보자.
MT output이 얼마나 괜찮은지 측정하는 한가지 방법은 출력된 각 단어를 보고 reference 안에 그 단어가 존재하는지 살펴보는 것이다. 이것을 MT output의 Precision(정밀도)라고 부른다.
MT output : 'the the the the the the the'에서 7개의 단어가 있으며, 이 단어는 Ref1이나 Ref2에 모두 나타난다.
따라서 이 단어들은 꽤 괜찮은 단어처럼 보일 수 있고, 정밀도는 7/7이 된다. 결과만 봐선 아주 좋은 결과같아 보인다.
이 MT output이 매우 정확하다는 것을 의미하지만 이것은 보다시피 유용한 방법이 아니다.
대신, 우리가 사용할 것은Modified Precision이다. 이 방법은 각 단어에 대해서 중복을 제거하고, reference 문장에 나타난 최대 횟수만큼 점수를 부여한다. Ref1에서는 'the'가 2번 나타나고, Ref2에서는 'the'가 1번 나타난다. 따라서, Modified precision은 2/7가 된다.
방금까지 우리는 각 단어를 개별적(isolated word)으로 살펴보았다. 즉, 단어의 순서를 고려하지 않았다.
Bleu Score로 평가할 때, 단어 쌍으로 Bleu Score를 정의해서 사용할 수 있다.
bigrams에서 Bleu score는 MT output의 각 단어들을 서로 근접한 두 개의 단어들로 묶어서, Reference에 얼마나 나타나는지 체크해서 Modificed Precision을 계산한다.
즉, MT output 에서 각 단어 쌍들의 Count와, MT output의 단어쌍들이 Reference에 얼마나 등장하는지 Count해서 계산하게 된다.
unigrams와 bigrams에서 bleu score를 구하는 방법을 살펴보았고, n-grams로 확장하면 다음과 같이 계산할 수 있다.
만약 MT output이 Ref1이나 Ref2와 정확히 같다면,P_1, P_2P1,P2는 1.0과 같다.
최종 Bleu Score를 만들기 위해서P_nPn을 합치도록 한다.
p_npn이 n-grams에서 bleu score고, 만약 1,2,3,4-grams를 사용한다면, 최종 Bleu score는 아래와 같이 계산될 수 있다.
대부분의 기계번역은 Encoder-Decoder Architecture를 사용하고 있고, 하나의 RNN에서 입력 문장을 읽고, 다른 RNN에서 문장을 출력한다. 이 아키텍처에서는 일반적으로 짧은 문장에서 잘 동작하고, 입력 문장의 길이가 길어질수록 성능이 낮아져서 Bleu score가 낮아지는 것을 볼 수 있다(파란색 그래프).
여기에 Attention model을 사용하면 긴 문장에서도 성능을 유지할 수 있게 된다(초록색 그래프).
사람이 번역할 때, 문장 전체를 외워서 처음부터 번역하는 것이 아닌 중간중간 번역하는 것처럼 Attention model은 사람과 유사하게 번역한다. 매 예측시점마다 인코더에서의 입력 문장을 다시 참고하는데, 이때, 전체 입력 문장을 참고하는 것이 아닌 예측할 단어와 연관되는 부분만 집중해서('Attention') 참조하게 된다.
Attention model은 처음에 기계번역 용도로 개발되었지만, 여러 App 영역에서도 적용되고 있다.
그렇다면 Attention model이 어떤 방식으로 동작하는지 간단하게 살펴보자.
우선 Encoder에 해당하는 RNN model(BRNN)이 있다. 그리고 Decoder에 해당하는 RNN model을 사용하는데, 여기에 사용되는 activation을 헷갈리지 않기 위해서 s로 표기한다.
간략하게 위 슬라이드를 설명하면, BRNN(Encoder)을 통해서 계산된 activation을 사용해서 C를 구하는데, 이때 일부 activation만 참조한다. 그리고, C를 Decoder의 입력으로 사용해서 단어를 예측한다. C를 계산하는 방법은 잠시 후에 설명하도록 한다.
다음 단어들도 동일한 방법을 사용해서 각 단어들을 예측하게 된다.
Attention Model
Attention model은 이름에서 알 수 있듯이 입력의 일부에 집중(attention)하도록 하는데, 첫 번째 단어를 예측하는 과정이 위 슬라이드에서 보여주고 있다.
그렇다면 attention parameter인α<t,t′>은 어떻게 계산될까?
Attention parameter는 softmax 확률로 계산되며, 따라서 총합이 1이 되는 것이다.
여기서e<t,t′>은 작은 신경망(Dense layer)을 통해서 구할 수 있으며, 이전 layer의 hidden activations^{<t-1>}s<t−1>과a^{<t'>}a<t′>를 입력으로 한다. (현재 단계에서 구하려고 하는 activation이s^{<t>}s<t>이기 때문에 이전 layer의 hidden activation을 사용)
Attention model의 단점은 학습시간(연산량)이 quadratic time(cost)을 가지게 된다는 것이다. 만약T_xTx의 입력 문장과T_yTy의 output 문장이 있다면 attention 파라미터의 총 개수는T_x \times T_yTx×Ty가 된다. (이러한 cost를 절감하기 위한 논문도 존재한다.)
간단하게 attention model을 살펴보았는데, 이 아이디어는 다른 영역에서도 적용되었는데, Image Captioning(이미지캡션)에서 적용이 되었다.
Attention example로 date normalization도 있다.
Speech Recognition
음성 인식은 오디오 클립 x를 통해서 transcript를 찾는 것이다. 이 문제를 해결하기 위해서 일반적으로 입력 데이터를 주파수별로 분리하는 것이다. 오디오 클립의 아래 그래프는 x축은 시간이고, y축은 주파수인 그래프를 나타낸다. 일반적으로 이렇게 전처리를 적용하는 경우가 많다.
그래서 어떻게 음성 인식 시스템을 구현할 수 있을까?
방금 배웠던Attention model을 음성 인식 모델에 사용할 수 있다.
또 다른 방법으로는 음성 인식을 위해서 CTC Cost를 사용하는 것이다.
CTC는 Connectionist temporal classification을 의미한다.
CTC Cost를 사용하면, RNN에서 ttt_h_eee와 같은 출력을 얻을 수 있고, '_'는 blank를 의미한다. 그리고 CTC Cost의 기본 규칙은 'blank'로 구분되지 않는 반복된 문자를 제거하는 것이고, 위의 예시에서는 output이 'the q'가 될 것이다.
Trigger Word Detection
Trigger word detection은 기계를 깨울 수 있는 방법을 의미한다.
Trigger word detection은 여전히 발전하고 있기 때문에, 현재 최선의 알고리즘에 대해서 논의가 이루어지고 있다.
우리가 사용할 수 있는 Trigger word 알고리즘 예시를 하나 살펴보자.
위의 RNN 모델을 보면, 오디오 클립 x가 입력으로 사용된다. 그리고 우리는 label y를 정의하는데, trigger word를 누군가가 말할 때, trigger word를 말하기 전의 시점은 모두 label을 0으로 설정하고, 말하고 난 직후 시점을 1로 label할 수 있다.
하지만, 이 경우에는 실제로 잘 동작하지 않는다. 왜냐하면, label의 불균형하게 분포하고 있기 때문인데, 1에 비해서 0이 훨씬 더 많다. 그래서, 단 한번이 아닌 label 1의 비율을 늘려서 출력하도록 할 수 있다.
저번주 강의에서 RNN, GRU, LSTM에 대해서 배웠고, 이번주에서는 NLP에 어떤 아이디어들을 적용할 수 있는지 살펴보도록 할 것이다.
NLP에서 중요한 아이디어 중의 하나는 Word Embedding(단어 임베딩)이다.
지난 주에 사용했던 1만개의 단어에 대해서 우리는 one-hot encoding을 통해서 단어를 표시했다.
즉, Man은 5391의 index를 갖고 있으며, 10000 dimension의 벡터에서 5391번째 요소만 1이고 나머지는 다 0으로 표시되는 벡터로 나타낼 수 있다.o5391로 나타내며, o는 one-hot vector를 의미한다.
one-hot encoding의 약점 중의 하나는 각 단어를 하나의 object로 여기기 때문에 단어 간의 관계를 추론할 수 없다는 것이다. 예를 들어, I want a glass of orange _______ 를 통해서 빈칸에 juice가 들어가도록 학습했다고 하더라고, I want a glass of apple _______ 이라는 입력이 들어왔을 때, apple을 orange와 비교해서 비슷하다고 여겨서 juice를 추론할 수가 없다는 것이다.
두 개의 서로 다른 one-hot vector 사이에서의 곱셈 결과는 0이기 때문에, king/queen, man/woman 같은 관계를 학습할 수 없다.
따라서, 위와 같은 문제를 해결하기 위해서 Word Embedding을 통해서 각각의 단어들에 대해 features와 values를 학습하는 것이 필요하다.
단어 임베딩은 위와 같은 matrix를 갖는다. row는 feature들을 의미하고, Gender/Royal/Age/... 등이 될 수 있다. 각 col은 보카에 존재하는 단어들이다.
그래서 Man이라는 단어를 보면 Gender에 해당하는 값이 -1에 가깝고, Woman은 1에 가까운 것을 볼 수 있다. 서로 반대되는 개념이기 때문에 두 합이 0에 가깝게 되는 것이다. Apple이나 Orange의 경우에는 성별과 거의 연관이 없기 때문에 Gender에 해당되는 값이 0에 가까운 것을 확인할 수 있다.
이처럼 워드 임베딩을 통해서 각 특징에 대한 값들을 갖는 임베딩 행렬(Embedding Matrix)를 얻을 수 있다.
Man의 임베딩 벡터는e5391로 표현할 수 있고, e는 embedding을 의미한다.
I want a glass of orangejuice.
I want a glass of apple _______.
워드 임베딩을 통해서 juice 앞의 apple과 orange과 유사하다는 것을 추론할 수 있기 때문에 apple 다음에 juice가 온다는 것을 더 쉽게 예측할 수 있다.
다만, 워드 임베딩에서 각 row가 어떤 특징을 의미하는지 해석하기는 어렵지만, one-hot encoding보다 단어간의 유사점과 차이점을 더 쉽게 알아낼 수 있는 장점을 갖고 있다.
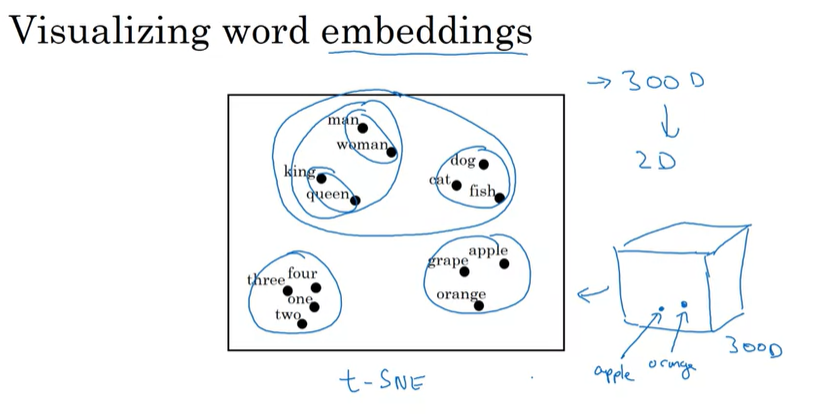
보통 feature의 개수로는 300 dimension을 많이 사용한다.
이렇게 300 dimension의 워드 임베딩 행렬을 조금 더 쉽게 이해하기 위해서 시각화를 할 수 있는데, 이 시각화 작업을 위해 사용되는 알고리즘은t-SNE 알고리즘이다.
t-SNE 알고리즘은 임베딩 행렬을 더 낮은 차원으로(여기서는 2D) 매핑해서 단어들을 시각화하며, 유사한 단어들을 서로 가까이에 있는 것을 확인할 수 있다.
Using Word Embeddings
기존의 이름을 인식하는 예제를 가지고 살펴보자.
'Sally Johnson is an orange farmer'라는 example에서 Sally Johnson이 이름이라는 것을 확실히 하기 위한 방법 중의 하나는 orange farmer가 사람임을 알아내는 것이다. one-hot encoding이 아닌 word embedding을 사용해서 학습한 후에, 새로운 example 'Robert Lin is an apple farmer'에 대해서 apple이 orange와 유사하다는 것을 알기 때문에 Robert Lin이 사람 이름이라는 것을 더 쉽게 예측할 수 있다.
만약 apple farmer가 아닌 많이 사용되지 않는 과일인 'durian cultivator'라면 어떻게 될까?
training set의 수가 적고, training set에 durian과 cultivator가 포함되지 않을 수 있다. 하지만, durian이 과일이라는 것을 학습하고, cultivator가 사람을 나타낸다는 것을 학습한다면 training set에서 학습한 orange farmer에서 학습한 것을 durian cultivator에도 일반화하게 될 것이다.
단어 임베딩이 이렇게 일반화할 수 있는 이유 중의 하나는 단어 임베딩을 학습하는 알고리즘이 매우 큰 단어 뭉치들을 통해서 학습하기 때문이다.(10억~1000억개의 단어)
또한, 우리가 적은 수의 training set을 가지고 있다고 하더라도, Transfer Learning을 통해서 미리 학습된 단어 임베딩을 가지고 학습할 수 있다.(꽤 좋은 성능을 보여준다)
일반적인 NLP 작업에서 단어임베딩은 위와 같은 과정으로 진행된다. 하지만, Laguage model이나 Machine Translation에는 유용하지 않다. 앞서 배운 Transfer Learning처럼, A의 data는 많고 B의 data는 적을 때 더욱 효과적이다.
단어 임베딩은 Face encoding과 유사하다고 볼 수 있다.
앞서 CNN 강의에서 봤던 face encoding의 슬라이드인데, 이미지를 128D vector로 변환해서 이미지들을 비교하게 된다.
한가지 차이점은 사진의 경우에는 처음보는 이미지더라도 encoding이 되지만, 단어 임베딩의 경우에는 입력으로 사용되는 단어가 정해져있기 때문에 UNK과 같은 알 수 없는 단어(voca에 존재하지 않는)가 포함된다. 즉, 정해진 단어만 학습한다는 의미이다.
Properties of Word Embeddings
단어임베딩의 중요한 부분은 이것이 유추하는 문제에 큰 도움을 준다는 것이다. 이에 대한 예제를 통해서 단어 임베딩의 특징을 살펴보자.
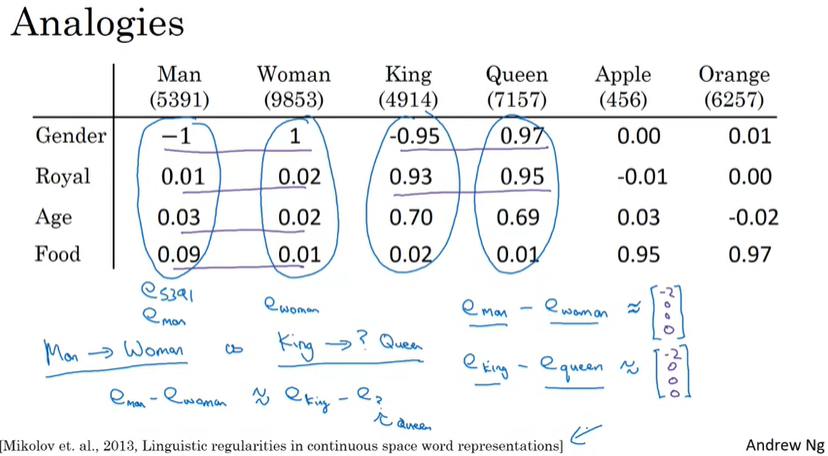
'남자(man)와 여자(woman)는 왕(king)과 ____과 같다'라는 유추 문제가 있을 때, 어떻게 예측할 수 있을까?
위 표와 같이 Man은4차원벡터로 표현되며,e_{5391} = e_{man}e5391=eman으로 나타낼 수 있다. 그리고 woman의 임베딩은e_{woman}ewoman으로 표현하며, king/queen도 동일하게 표현된다. (실제로는 50~1000 차원을 사용한다)
이 결과에 의해서 우리는 man과 woman의 관계가 king과 queen의 관계와 유사하다고 추론할 수 있다.
직관적으로 이해하기 위해서 아래 슬라이드를 참조하자.
단어 임베딩은 약300차원의 공간에서 표현될 것이고, 그 공간 안에서 각 단어들은 점으로 표현될 것이다.
그리고, man과 woman의 차이와 king과 queen의 차이 벡터는 매우 유사할 것이다. 위에서 나타난 벡터(화살표)는 성별의 차이를 나타내는 벡터를 의미한다. 주의해야할 점은 300차원 안에서 그려진 벡터이다.(2차원이 아님)
여기서 우리가 해야할 것은 'man -> woman as king -> _____' 에서 우리는 빈칸의 단어 w를 찾는 것이고, 아래 방정식으로 찾을 수 있다.
여기서 sim은 similarity function을 의미하며, 두 단어 사이의 유사성을 계산한다. 위 식에서 유사성을 최대화하는 단어를 찾게 되고, 따라서 queen이라는 단어라고 예측할 수 있을 것이다.(적절한 similarity function이 필요하다)
실제 논문에서는 30~75%의 정확성을 보여주고 있는데, 유추 문제에서 완전히 정확한 단어를 추론했을 경우에만 정답으로 인정하기 때문이다.
그리고 t-SNE 알고리즘에 대해서 언급하자면, 이 알고리즘은 300D을 2D로 매핑하는데, 매우 복잡하고 비선형적인 매핑이다.따라서 임베딩을 통해서 단어간의 관계를 추론할 때, t-SNE를 통해 매핑된 임베딩 값으로 비교하면 안되고, 300D의 vector를 통해서 비교 연산을 수행해야한다.
일반적으로 Similarity function으로는 Cosing similarity를 가장 많이 사용한다.
또한 유클리디안 거리를 사용하기도 한다.
Embedding Matrix
단어 임베딩을 통해서 학습되는 것은Embedding Matrix이다. 만약 1만개의 단어를 사용하고 특징으로 300 차원을 사용한다면 위와 같은 (300, 10k)의 차원의 matrix E를 가지게 된다. 그리고 voca에 담겨있는 10000개의 단어들을 각각 다르게 임베딩한다. 예를 들어, orange는 6257 column에 있으며, 이 열은 orange에 해당하는 임베딩 vector가 된다. 그리고 one-hot encoding을 통한o6257을 matrix E와 dot product를 수행하면 우리가 원하는 6257 column의 orange의 임베딩 vector를 얻을 수 있다. => E * o6257 =e6257
일반화하면 다음과 같다.
우리가 학습해야되는 것이 Embedding Matrix E라는 것이 가장 중요하며, 이 Matrix E는 초기에 무작위로 초기화된다.
하지만 위 공식에서 Matrix E를 one-hot vector o와 함께 곱하는 것으로 표현되어있는데, 이것은 꽤 비효율적이다. one-hot vector는 꽤 높은 차원인데, 대부분 0으로 채워져있기 때문에 메모리 낭비가 심하고, 연산량도 많다.
실제로는 one-hot vector를 곱하는 것이 아닌 특화된 함수를 사용한다.
Learning Word Embeddings
단어 임베딩(Word Embedding) 딥러닝 연구에서 초반에는 비교적 복잡한 알고리즘으로 시작했다. 그리고 시간이 지나면서, 훨씬 더 간단하고 단순한 알고리즘도 가능하고, 특히 큰 데이터셋에서 매우 좋은 결과를 얻을 수 있다는 것을 발견하게 되었다. 최근 가장 인기있는 몇몇의 알고리즘들은 너무 단순해서 마치 마법처럼 보일 수도 있을 정도이다.
단어 임베딩이 어떻게 동작하는지 직관적으로 이해하기 위해서 더 복잡한 알고리즘의 일부를 살펴보도록 하자.
Language model을 만들고, I want a glass of orange _______. 에서 orange 다음의 단어를 예측하려고 한다.
주어진 단어들은 위와 같은 index를 가지도록 했다.
Neural language model은 embedding을 학습할 수 있는 방법이라고 밝혀졌다. 그리고 신경망 모델을 만들어서 연속적인 단어들을 통해서 다음 단어를 예측할 수 있는데, 첫번째 단어부터 시작해보자.
첫번째 단어 I의 one-hot vectoro4343이 있고, Matrix E를 통해서 vectore4343을 얻을 수 있습니다. 다른 모든 단어도 동일하게 Matrix E를 통해서 vector를 얻을 수 있다. Matrix E를 통해서 얻은 vector들은 모두 300차원 vector이고, 이것을 신경망의 입력으로 사용하고 그 output은 softmax를 통해서 voca의 확률들로 변환된다.
신경망과 softmax layer는 각각의 weight와 bias 파라미터가 있고,각 단어들은 300차원의 vector이므로 입력은 총 1800차원의 벡터가 된다.
일반적으로 fixedhistorical window를 사용하는데, 예를 들어, 다음 단어를 예측하는데 그 단어 앞의 4개의 단어만 사용하는 것이다. 따라서, 긴 문장이나 짧은 문장이나 항상 바로 앞의 4개의 단어만 살펴보는 것이다. 이것은 입력으로 1200차원의 vector를 사용해서 softmax output으로 예측하는 것을 의미한다.
여기서 4개의 단어 사용은 하이퍼 파라미터로 설정할 수 있고, 이렇게 고정된 범위의 단어를 사용한다는 것은 입력의 크기가 항상 고정되어 있기 때문에 임의의 긴 문장들을 다룰 수 있다.
따라서, 이 모델의 파라미터는 Matrix E와W[1],b[1],W[2],b[2]가 되며, Matrix E는 모든 단어에 동일하게 사용된다.
이 알고리즘은 꽤 괜찮은 word embedding을 학습하게 되고, 만약 orange가 아닌 apple이나 durian이 오더라도 유사한 단어라면 juice를 예측할 수 있게 되는 것이다.
중요한 것은Matrix E를 학습한다는 것이고, 이제 이 알고리즘을 일반화해서 어떻게 더 단순한 알고리즘을 도출할 수 있는지 살펴보자.
좀 더 복잡한 문장 I want a glass of orange juice to go along with my cereal 이 있고, juice를 예측한다고 할 때, target은 juice가 된다. 그리고 앞서 살펴봤듯이 language model을 구성할 때, 입력으로 바로 앞의 4개의 단어를 선택했는데, 왼쪽과 오른쪽 4개의 단어를 선택할 수도 있고, 다른Context를 선택할 수도 있다.
조금 더 단순하게 사용한다면 마지막 한 단어만 선택할 수도 있고, 가장 가까운 단어 하나를 사용할 수도 있다.
다음 영상에서 더 간단한 Context와 더 간단한 알고리즘을 통해서 어떻게 target word를 예측하게 되는지, 어떻게 좋은 단어 임베딩을 학습할 수 있는지 살펴보자.
Word2Vec
Word2Vec는 단어를 벡터로 바꾸어주는 알고리즘이고, 그 방법중의 하나인 Skip gram에 대해 알아보자.
Skip gram은 중심이 되는 단어를 무작위로 선택하고 주변 단어를 예측하는 방법으로, 중심 단어(Target)를 바탕으로 주변 단어(Context)들을 예측하는 superivsed learning이다. (주변 단어는 여러개를 선택할 수 있다)
다음으로 Skip gram의 모델이다.
1만개의 voca가 있고, 이 단어들을 통해서 Context c에서 Target t를 매핑하는 모델을 학습해야 한다.
입력과 결과의 예를 들면, orange와 juice가 될 수 있다.
이전 강의에서 본 것처럼, 단어들의 one-hot vector와 Embedding Matrix E를 통해서 Embedding vector를 구할 수 있다. 그리고 이렇게 구한 Embedding vector를 입력으로 softmax layer를 통과해서 output y^를 구할 수 있다.
하지만, 이 skip gram model에는 몇 가지 문제가 존재하는데, 주된 문제는 바로 계산 속도이다.
특히 softmax model의 경우에 확률을 계산할 때 1만개의 단어를 계산해야한다. (p(t|c)p(t∣c)의 분모항)
만약 10만개, 또는 100만개의 단어를 사용한다면 매번 분모를 합산하는 것은 매우 느리다.
이에 대한 몇 가지 해결 방법이 존재하는데, 그 중 한가지가hierarchical softmax를 사용하는 것이다.
이 방법은 Tree를 사용하는 것인데, 자주 사용되는 단어일수록 Tree의 Top에 위치하고, 그렇지 않다면 Bottom에 위치하게 된다. 따라서 어느 한 단어를 찾을 때, Tree를 찾아 내려가기 때문에 선형 크기가 아닌 voca 사이즈의 log 사이즈로 탐색하게 되어 softmax보다 빠르다. 자세한 내용은 논문을 참조하면 된다.
Word2Vec의 또 다른 방법은 Negative Sampling인데, 이것에 대해 설명하기 전에어떻게 Context c를 샘플링하는 지에 대해서 이야기를 해보자.
Context c를 샘플링하면, Target t를 context의 앞뒤 10단어 내에서 샘플링할 수 있다. 여기서 context c를 선택하는 한가지 방법은 무작위로 균일하게 샘플링하는 것이다. 하지만, 이렇게 무작위로 하게 된다면 the, of, a, to 등이 아주 빈번하게 샘플링된다. 따라서 샘플링할 때에는 빈번한 단어들과 그렇지 않은 단어들간의 균형을 맞추기 위해서 다른 방법을 사용해야 한다.
Negative Sampling
지금까지 Skip gram 모델을 살펴보았는데, skip gram 모델은 softmax 연산이 너무 느린 문제점이 있었다.
다음으로 skip gram과 유사한 Negative Sampling이라는 알고리즘에 대해서 살펴볼 것인데, 이것이 skip gram보다 조금 더 효율적이다.
Negative sampling은 새로운 학습 문제를 정의한다. 예를 들어서 문제로 orange-juice와 같은 positive training set이 있다면, 무작위로 negative training set을 K개를 샘플링한다. 이때, 무작위로 negative 단어를 선택할 때에는 voca에 존재하는 단어 중에서 무작위로 선택하면 된다.
하지만, 우연히 'of'라는 단어를 선택할 수도 있는데, 이는 context에 존재하는 단어이므로 실제로는 positive이지만, 일단 negative라고 취급한다.
negative sampling은 이렇게 training set을 생성하게 된다.
이 방법을 사용할 때에 작은 데이터 셋의 경우에는 K를 5~20의 값으로 추천하고, 큰 데이터 셋을 가지고 있다면 K를 더 작은 값인 2~5의 값으로 추천한다. 위 슬라이드에서는 K=4로 설정했다.
다음은 x->y mappling model이다.
앞서 본 softmax model이 있고, 이전 슬라이드에서 선택한 training set가 있다. 즉 context와 target이 input x가 되고, positive와 negative는 output y가 된다. 그래서 우리는 logistic regression model로 정의할 수 있게 된다.
이렇게 하면 1만 차원의 softmax가 아닌 1만 차원의 이진분류 문제가 되어서 계산량이 훨씬 줄어들게 된다.
그리고 모든 iteration과정에서 한개의 positive와 K개의 negative 샘플만 학습하고 있다.
이 알고리즘에서 가장 중요한 점은 어떻게 negative sample을 선택하느냐인데, 한 가지 할 수 있는 방법은 말뭉치(corpus)에서의 empirical frequency(경험적 빈도)에 따라서 샘플링하는 것이다. 그래서 얼마나 자주 다른 단어들이 나타나는 지에 따라서 샘플링할 수 있다. 문제는 the, a, of, to와 같은 단어들이 자주 나타날 수 있다는 것이다.
또 다른 극단적인 방법은 1/voca size를 사용해서 무작위로 샘플링하는 것이다. 이 방법은 영어 단어의 분포를 생각하지 않는다.
논문의 저자는 경험적으로 가장 좋은 방법을 직접 찾아서 사용하는 것이 좋다고 한다. 논문에서는 단어 빈도의 3/4제곱에 비례하는 샘플링을 진행했다.
Glove Word Vectors
단어 임베딩의 또 다른 알고리즘은 GloVe 알고리즘이다. Word2Vec or skip gram model만큼 사용되지는 않지만, 꽤 단순하기 때문에 사용된다.
GloVe는 gloval vectors for word representation를 뜻한다.
GloVe 알고리즘은 말뭉치(corpus)에서 context와 target 단어들에 대해서 i의 context에서 j가 몇 번 나타내는지(X_{ij}Xij) 구하는 작업을 한다. 즉, 서로 가까운 단어를 캡처하며, context와 target의 범위를 어떻게 지정하느냐에 따라서X_{ij} == X_{ji}Xij==Xji가 될 수도 있고, 아닐 수도 있다.
위 식에서f(X_{ij})f(Xij)를 설정하는데, 이는 weighting term이고, 이것이 하는 일은 한번도 등장하지 않는 경우에는 0으로 설정해서 더하지 않게 해주고, 지나치게 빈도가 높거나 낮은 단어로 인해서X_{ij}Xij값이 특정값 이상으로 튀는 것을 방지하는 역할을 한다.
마지막으로 이 알고리즘에서 흥미로운 점은\theta_i와 e_jθi와ej가 완전히 대칭적이라는 것이다.
Sentiment Classification
Sentiment classification(감성 분류)는 NLP에서 중요한 구성요소 중의 하나이다. 감성 분류에서 중요한 점은 많은 dataset이 아니더라도 단어 임베딩을 사용해서 좋은 성능의 분류기를 만들 수 있다는 것이다.
Sentiment classification problem은 위와 같은 매핑 문제이다.
간단한 모델은 아래와 같이 구성할 수 있다.
'The dessert is excellent'라는 입력이 있을 때, 각 단어들을 임베딩 vector(300D)로 변환하고 각 단어의 벡터의 값들의 평균을 구해서 softmax output으로 결과를 예측하는 모델을 만들 수 있다.
여기서 단어 임베딩을 사용했기 때문에, 작은 dataset이나 자주 사용되지 않는 단어(심지어 학습에 사용되지 않는 단어)가 입력으로 들어오더라도 해당 모델에 적용이 가능하다.
하지만 위 모델은 단어의 순서를 무시하고 단순 나열된 형태로 입력하기 때문에 별로 좋은 모델은 아니다.
예를 들어 'Completely lacking in good taste, good service, and good ambience'라는 리뷰가 있다면, good이라는 단어가 많이 나왔기 때문에 positive로 예측할 수도 있다는 것이다.
그래서 해당 문제점을 해결하기 위해서 RNN을 사용할 수 있다.
방금 예시처럼 부정의 리뷰를 입력으로 사용하더라도 시퀀스의 순서를 고려하기 때문에 해당 리뷰가 부정적이라는 것을 알 수 있게 된다. 따라서 이 모델로 학습하면 상당히 괜찮은 분류기가 된다. 또한 absent라는 단어가 training set에 존재하지 않았더라도 단어 임베딩에 포함이 된다면, 일반화되어서 제대로 된 결과를 얻을 수 있다.
Debiasing Word Embeddings
Machine Learning과 AI 알고리즘은 매우 중요한 결정을 하는데 도움이 되거나, 많은 도움을 줄 수 있다고 신뢰받고 있다. 그래서 우리는 bias(편견)에서 자유롭다는 것을 확인하고 싶어한다.(예를들어, 성이나 인종에 대한 편견을 가지지 않는 알고리즘이기를 원한다.)
이번 강의에서는 단어 임베딩에서 이러한 편견들이 있을때, 어떻게 이런 편견들을 제거하거나 감소시키는 방법에 대해서 알아보도록 하자.
단어 임베딩에서 성별이나 나이, 인종 등의 편견을 반영하기 때문에 이것을 없애는 것은 매우 중요하다. (많은 결정에서 AI가 사용되므로)
단어 임베딩에서 편견은 다음과 같은 과정을 거쳐서 제거할 수 있다.
1. 먼저 bias의 direction을 구한다.
만약 성별의 direction을 구한다면,e_{he} - e_{she}, e_{male}-e_{female}ehe−eshe,emale−efemale등의 성별을 나타낼 수 있는 단어들의 차이를 구해서 구할 수 있는데, 남성성의 단어와 여성성의 단어의 차이를 구해서 평균으로 그 방향을 결정할 수 있다.
(실제로는 더 복잡한SVD-특이값분해라는 알고리즘을 통해서 bias direction을 구한다)
그리고 이것은 1D의 bias direction과 나머지 299D의 non-bias direction으로 나눌 수 있다.
2. 다음으로는 Neutralize(중성화) 작업을 수행한다.
bias가 없어야 하는 단어들에 대해서 bias 요소를 제거해야하는데, project를 통해서 각 단어 벡터의 bias direction 요소를 제거한다. doctor나 babysitter등의 단어의 성별 bias를 제거하는 것이다.
3. 마지막으로 Equalize pairs 작업을 수행한다.
즉, boy-girl / grandfather-grandmother과 같은 단어는 각 단어가 성별 요소가 있기 때문에, 이러한 단어들이 bias direction을 기준으로 같은 거리에 있도록 한다. 즉, 각 성별 요소가 있는 단어들은 bias direction과의 거리의 차이가 동일하도록 만들어주는 것이다.
전체 알고리즘은 조금 더 복잡한데, 논문에서 자세하게 설명하고 있으며, 또한 실습을 통해서 직접 수행해보도록 할 것이다.
독립변수간의 상관관계가 매우 높을 때, 하나의 독립변수의 변화가 다른 독립변수에 영향을 미쳐, 결과적으로 모델이 크게 흔들리는 것을 의미한다. 모델의 결과는 불안정하며 작은 변화에도 변동이 크다. 이는 다음과 같은 문제를 야기시킨다:
1. 모델이 예측을 할 때마다, 다른 결과를 준다면, 중요 변수들의 묶음에서 어떤것을 골라야할지 어려움
회귀계수 추정치는 안정적이지 않고, 그 결과 모델에 대한 해석이 어려움. 즉, 독립변수 1단위가 변화했을 때, 종속변수가 얼마나(scale) 변화했는지 말할 수 없다.
모델의 불안정성은 오버피팅을 유발할 수 있다. 만약 다른 데이터 샘플을 적용하면, 정확도는 학습데이터의 정확도보다 크게 낮아질 것이기 때문이다.
Dummy variable trap
옳지 않은 더미변수 사용은 다중공선성문제를 야기할 수 있다.
예를 들어, 결혼상태 변수에 대한 데이터셋이 있다고 하자. 결혼 상태 변수는 기혼/미혼, 두 가지 unique value를 가진다. 이 두 value에 대해서 각각 더미변수를 만들게 되면, redundant information문제를 야기하므로, 결혼 상태에 대한 더미변수 하나를 만들어, 기혼:0, 미혼:1 로 설정해야한다.
다중공선성 문제가 발생했는지 어떻게 알 수 있는가?
1) correlation matrix를 그려보자
수많은 독립변수 중 어떤 것을 선택해야될 지 모르겠을 때는, 종속변수도 correlation matrix에 포함시켜서, 종속변수와 가장 높은 상관관계를 가지는 독립변수를 선택하라.
2) VIF를 확인하자
각각의 독립변수에 대한 VIF를 구해보자. VIF값이 클 수록, 해당 독립변수와 나머지 독립변수간의 상관관계가 높아진다.
VIF
머신러닝에서의 다중공선성
어떤 학습데이터로 모델을 학습시켰다고 하자. 그리고 우리는 테스트셋에 대해서 예측을 할 것이다. 학습셋과 테스트셋의 변수간에 공분산이 다르다면, 우리의 학습데이터에 있는 다중공선성은 예측 성능을 저하시킬 것이다. 만약 학습과 테스트셋에서 공분산 구조(covariance structure)가 비슷하다면, 문제를 발생시키지 않을 것이다. 테스트셋이 보통 전체 데이터셋(full dataset)의 랜덤한 부분 집합이기 때문에, 공분산 구조가 같을 것이라고 가정하는 것이 reasonable하다. 그러므로, 다중공성성은 이러한 목적에서는 큰 문제가 되지 않는다.
한 가지 예를 생각해보자. 당신이 어떤 그룹의 사람들의키를 다른 변수들(몸무게, 팔길이, 다리길이 등)으로 예측한다고 생각해보자. 당신은 이 변수들이 매우 강한 상관관계가 있다는 것을 발견하게 될 것이다. 하지만, 당신이 이러한 변수들(팔길이, 다리길이, 몸무게 등)이 학습/테스트셋에서 동일한 정도의 상관관계를 보일 것으로 가정한다면, 당신은 분석을 계속해서 테스트셋의 사람들의 키를 예측할 수 있을 것이다. 만약 학습/테스트셋 간의 공분산 구조가 다르다면 예측은 좋지 못할 것이다.
예측문제에서의 다중공선성은 문제가 되지 않지만, 추론문제에서의 다중공선성은 문제가 있다. 두 변수 x1, x2가 perfectly correlated(r=1)된 경우를 생각해보자. x1 -> y과 x2 -> y, 두 개의 회귀분석을 진행했을 때, 동일한 회귀계수값을 반환할 것이다(두 회귀분석에서 도출된 동일한 회귀계수를 3이라고 하자) 다중회귀분석에서 y를 예측하기 위해 x1과 x2가 함께 쓰였다면,동일하게 valid한 가능한 회귀계수 조합의 범위가 무한하다.
예를 들어, x1의 회귀계수는 3이 될 수 있고, x2의 회귀계수는 0 이 될 수 있다. 역도 동일하게 valid하다.
이는 추론의 관점에서 거대한 불확실성을 가지고 온다. 왜냐하면 각각의 독립적인 parameter는 poorly 고정되어있기 때문이다. 그러나, 중요한 것은, hypothetical model 간의 x1과 x2의 큰 변동에도 불구하고, 모든 모델은 동일하다는 것이다. 만약 당신이 원하는 것이 새로운 값에 대한 예측이라면, 당신은 이 모델중 어떤것을 골라도 된다. 당신의 테스트셋에서, x1과 x2가 여전히 prefectly correlated되어있기 때문이다.
머신러닝에서의 다중공선성문제 해결
앞서, 다중공선성이 궁극적으로 오버피팅을 야기할 수 있다는 점을 지적하였다. 머신러닝에서 다중공선성 문제의 해결이 모델 예측의 정확성에 영향을 주지 않는 것은 아니다. 다만, 머신러닝에서는 오버피팅에 초점을 두고, 이를 해결하기 위해, regularization을 사용한다. 이러한 regularization 은 회귀계수의 안정화에 도움을 준다. 그리고 이는 적어도 어느정도는 다중공선성의 완화에 도움을 줄 것이다.
결론
ML 문제에서, 회귀계수 추정치에 대한 관심이 없고 예측에 대해서만 관심이 있기 때문에 학습/테스트셋 간의 공분산 구조가 동일하다는 가정하에서, 다중공선성이 예측에 악영향을 끼치지는 않는다. 그래서, ML문제에서 다중공선성을 크게 고려하지 않았던 것이다.
-> 더 나아가서, 이 점이 바로 전통적인 통계학과 머신러닝의 차이점을 시사한다고 할 수 있다. 전통적인 통계학은 모델에 대한 해석(inference)에 초점을 맞췄다면, 머신러닝을 모델을 통한 예측(predict)에 초점을 맞추는 것이다.