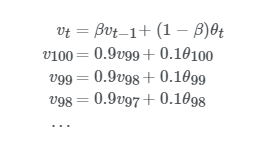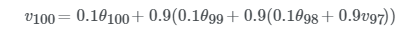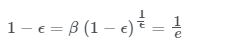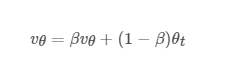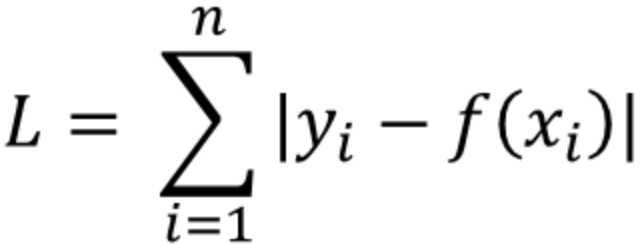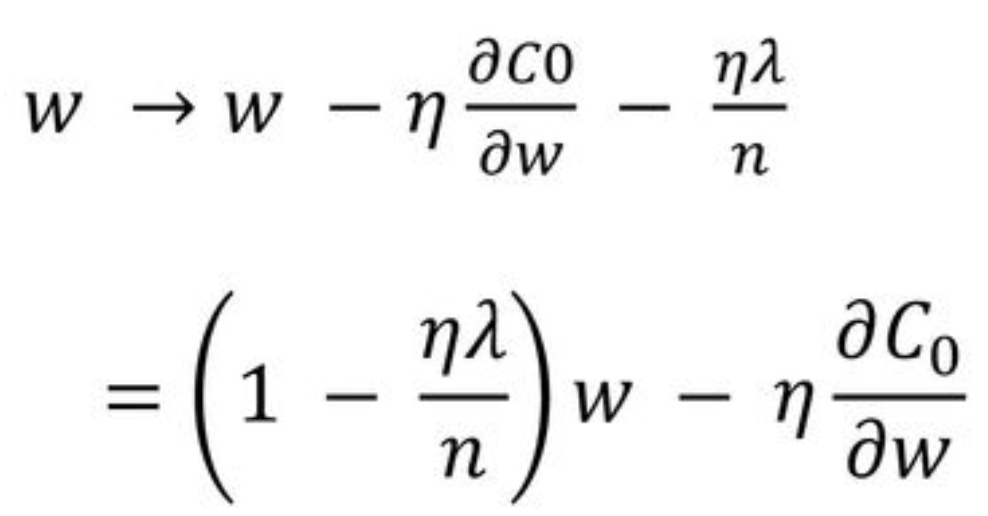dev set에서 모델 분석 결과 잘못 표기된 예시를 찾고 잘못 표기된 예시에서 거짓 양성과 거짓 음성을 찾습니다. 그 후 다양한 카테고리에 대한 오류의 총 개수를 각각 카테고리 별로 찾아 냅니다.
이렇게 수작업으로 분석하는 것은 시간이 꽤 긴 시간이 소요되는데, 그럼에도 불구하고 우리가 해야되는 것들 중에서 우선순위를 정하는데 많은 도움을 주고, 접근 방법에 대한 효율을 수치적으로 측정할 수 있다.
Cleaning Up Incorrectly Labeled Data
우선 training set에서 고려해보면, 딥러닝 알고리즘은 training set에서 random error에 대해서 상당히 견고하다는 것이 밝혀져있다. 따라서, 이렇게 잘못 레이블된 example들이 고의적으로 발생한 것이 아니라, 단순 실수에 의한 것이고 랜덤으로 발생되었다고 한다면, 이 error는 그대로 두어도 괜찮고, 고치는데 많은 시간을 쏟을 필요가 없다.
, 딥러닝 알고리즘은 systemic errors에 대해서는 문제가 발생할 수 있다. 예를 들어서, dataset의 레이블을 담당하는 사람이 지속적으로 흰색 강아지를 고양이로 레이블했다면, 분류기가 모든 흰색 강아지를 고양이로 분류하도록 배울 수 있기 때문에 문제가 될 수 있다.
만약 dev set이나 test set에서 잘못 레이블된 example들이 있다면 어떨까?
이런 문제가 우려스럽다면, 추천하는 방법은 Error Analysis를 진행하면서, 카테고리를 추가해서 잘못 레이블된 example의 %를 구하는 것이다.
(가끔 잘못 레이블된 example들을 살펴보면, 학습 알고리즘이 잘못 분류한 것이 아니라, 데이터를 레이블한 사람이 미처 뒷배경에 있는 고양이를 보지 못하고 잘못 레이블한 경우도 있을 수 있다.)
그렇게 잘못 레이블된 example의 %를 구한다. 그리고이 문제를 개선해서dev set에서 알고리즘의 성능이 현저하게 개선될 수 있다면 레이블이 잘못된 것을 수정하라고 이야기할 수 있지만, 그 성능이 크게 바뀌지 않는다면 효율적이지 않다.
전체적인 dev set error를 살펴보고 결정하는 것을 추천한다. 이전 예제처럼 10%의 dev error를 가지고 있고, 잘못 레이블된 이미지를 수정해서 개선한다면 10% error 중에서 6%, 즉, 0.6%를 개선할 수 있다는 것이다. 따라서 레이블을 수정한다고 해도 9.4%까지밖에 성능이 개선되지 않는다는 것이고, 이는 매우 비중이 작다고 볼 수 있다.
만약 잘못 레이블된 example의 비율이 30%이고, dev error가 2%라면, error의 30%는 0.6%이고, 레이블을 수정하면 error를 1.4%까지 줄일 수 있기 때문에 꽤 비중이 높다고 할 수 있고, 시도할만한 방법이라고 할 수 있다.
Build your First System Quickly, then Iterate
Set up dev/test set and metric
Build initial system quickly
Use Bias/Variance anylysis & Error analysis to priority next steps.
구체적으로 우선 dev/test set과 metric을 설정하는 것이다. 결국에는 목표를 어디에 둘지 설정하는 과정이다. 만약 잘못된 경우에는 언제든지 변경할 수 있다. 일단, 목표를 설정하고, 그 다음에 머신러닝 시스템을 우선 만든다. traing set를 수집하고, 학습한 다음 결과를 살펴본다. 그리고 dev/test set과 metric을 통해서 얼마나 잘 동작하는지 살펴보고 이해하는 것이다. 그런 다음에 Bias/Variance analysis나 Error analysis를 사용해서 다음 단계에 대한 우선순위를 지정해서 개선할 수 있다.
요약하자면, 초기 시스템으로 우선 학습을 완료하고, 학습 완료된 시스템을 통해 bias/variance를 조절하고, error analysis를 통해서 error를 살펴보고 많은 접근 방법 중에서 우선순위를 정해서 다음 과정을 진행하는 것을 반복하라는 것이다.
Training and Testing on Different Distributions
핵심은 dev/test set은 우리가 중점적으로 집중해야하는 데이터 분포도를 갖도록 하는 것이다. 즉 예를 들어, 모바일 앱에서 업로드된 사진을 분류하는 것이 목적이기 때문에, dev/test set의 분포도를 모바일 앱을 통한 이미지 분포도를 갖도록 하는 것이다. 하지만, 여전히 training data와 dev/test set의 분포도는 서로 다르다. 그러나 이렇게 나누어진 데이터에서의 결과가 장기적으로 훨씬 더 좋은 성과를 보인다.
Bias and Variance with Mismatched Data Distributions
학습 알고리즘의 bias와 variance를 추정하는 것은 다음 스텝으로 어떤 업무를 수행해야할 지에 대한 우선순위를 결정하는데 큰 도움을 준다. 하지만, 학습 알고리즘의 training set과 dev/test set이 서로 다른 분포도를 가지고 있다면 bias/variance를 분석하는 방법이 달라진다.
training-dev set은 training set에서 일부 추출한 데이터인데, training set과 동일한 분포도를 가지게 되지만, 이 데이터는 학습을 위한 데이터는 아니다.
위와 같이 데이터를 분배하게 되고, train과 train-dev는 서로 같은 분포도를 갖고, dev와 test가 서로 같은 분포도를 갖는다. 물론 train/train-dev와 dev/test의 분포도는 서로 다르다.
이렇게 분배한 후에, training set으로만 학습시키고, Error Analysis를 진행하기 위해서, training error, training-dev error, dev error를 구한다.
위 두가지 예시를 살펴보자.
왼쪽 예시는 training error가 1%, training-dev error가 9%, dev error가 10%이다. 결과를 보면 training -> training-dev error에서 많이 증가한 것을 볼 수 있고, 같은 분포도를 갖더라도 일반화가 잘 되지 않았다는 것을 볼 수 있기 때문에, 이 문제는 variance 문제가 있다고 볼 수 있을 것이다.
오른쪽 예시는 training error는 1%, training-dev error는 1.5%, dev error는 10%이다. 이 경우에는 training과 training-dev error의 차이가 크지 않으므로, low variance를 갖는다고 할 수 있으며, dev error에서 많이 증가한다. 이런 경우가 전형적인 data mismatch문제를 갖고 있다고 할 수 있다.
다음 두가지 예시를 더 살펴보자.
이번에는 human error까지 포함했는데, 왼쪽 예시는 human error가 0%, training error는 10%, training-dev error가 11%, dev error가 12%이다. bayes error가 0%라는 의미인데, training error와의 차이인 avoidable bias가 매우 큰 것을 볼 수 있고, bias 문제가 있다고 볼 수 있다.(high bias setting을 가지고 있음)
오른쪽 예시는 동일하게 human error가 0%, training error 10%, training-dev error 11%, 그리고 dev error가 20%이다. 이 경우에는 두 가지의 문제점이 존재한다. 첫 번째로 bayes error와 training error의 차이가 크기 때문에 avoidable bias문제가 존재하고, 두 번째는 training-dev error와 dev error의 차이가 크기 때문에 data mismatch의 문제도 있다고 볼 수 있다.
핵심은 human-level error, training error, training-dev error, dev error를 확인하고, 이 오류들의 차이를 분석해서 avoidable bias problem이나 variance, mismatch문제가 있는지 확인하는 것이다.
Addressing Data Mismatch
Error Analysis로 mismatch문제가 있다는 것을 알았을 때, 위와 같은 방법이 있다.
첫 번째로는 training set과 dev/test set이 어떤 차이가 있는지 수작업으로 error analysis를 수행하는 것이다. test set에 overfitting하는 것을 피하려면, dev set에서만 error analysis를 수행해야 한다.
예를 들어서, 백미러 음성인식 시스템을 개발하고 있다면, training set과 dev set을 비교해서 dev set이 보통 소음이 더 심하고, 자동차 소음도 많다는 점을 발견할 수도 있다. 이처럼 training set이 dev set과 어떻게 다른지 파악할 수 있다면, 이후에 traininig data를 dev set과 더 유사하게 만들 수 있는 방법을 찾을 수 있다.
두 번째 방법은 dev/test set과 유사한 데이터를 만들거나 또는 수집하는 것이다. 자동차 소음이 가장 큰 원인이라고 발견했다면, 차량 내에서 소음이 심한 데이터를 학습할 수 있다.
이렇게 분석을 해서 결국 training data를 dev set와 더 유사하게 만드는 것이 목표라면 우리가 할 수 있는 방법은 무엇이 있을까? 우리가 사용할 수 있는 방법 중에 하나는 인공적으로 데이터를 합성하는 것이 있다.(Artificial data synthesis)
하지만, 이 방법을 사용할 때 한가지 주의할 점이 있다. 만약 우리가 10,000시간 동안 소음없이 깨끗하게 녹음된 데이터가 있고, 자동차 소음 데이터가 1시간짜리가 있다면, 자동차 소음 데이터를 10,000번 반복시켜서 합성할 수 있다. 실제 차량에서는 다양한 소음들이 있지만, 이 경우에는 우리가 1시간짜리 소음에 대해서만 학습을 진행하게 된다면, 한 시간짜리 자동차 소음에 overfitting할 수도 있다. 10,000시간 동안의 자동차 소음을 수집하는 것이 가능할지는 모르겠지만, 1만 시간의 자동차 소음으로 합성을 한다면 더 좋은 성능을 낼 수 있을 것이다.
즉, 합성을 통해서 만든 데이터들이 단지 전체의 일부분이 될 수도 있다는 것이다. 따라서 합성한 데이터에 overfitting할 위험이 존재하고, 합성할 때에 이 부분을 유의해야 한다.
Transfer Learning
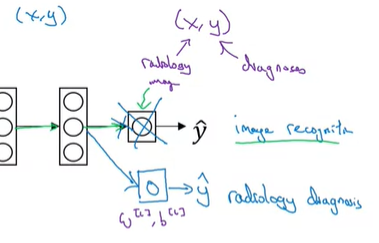
딥러닝의 강력함은 한 가지 Task에서 학습한 내용은 다른 Task에 적용을 할 수 있다는 것이다. 예를 들어서, Neural Network(NN)이 고양이와 같은 사진을 인식하도록 학습했을 때, 여기서 학습한 것을 가지고 부분적으로 X-ray 이미지를 인식하는데 도움이 되도록 할 수 있다. 이것이 바로 Transfer Learning이라고 한다.
이미지 인식 기능을 NN으로 학습을 했다고 해보자.xx는 이미지이고,yy는 some object(인식 결과)이다. 이미지는 고양이나, 개, 또는 새 등이 될 수 있다. 이렇게 학습한 NN을 사용해서 transfer한다고 표현하는데, 고양이와 같은 사진을 인식하도록 학습한 것이 X-ray Scan을 읽어서 방사선 진단에 도움이 될 수 있다. Transfer Learning은 다음과 같이 적용한다.
우선, 학습한 신경망 네트워크의 마지막 output layer를 삭제하고, 마지막 layer의 파라미터, weight(and bias)도 삭제한다. 그리고, 마지막 layer를 새로 만들고, 무작위로 초기화된 weight를 만든다. 이렇게 생성한 layer들을 통해서 진단의 결과값을 나타내는 것이다.
구체적으로 설명하자면, 이미지 인식 업무에 관련해서 파라미터를 학습을 시킨 것을 사용하는 것이고, 이 학습 알고리즘을 방사선 이미지에 transfer를 진행한다. data set (x, y)를 방사선 이미지로 바꾸어 주고, 마지막 output layer의 파라미터W^{[L]}, b^{[L]}W[L],b[L]을 초기화시킨다. 그리고 새로운 dataset에서 NN을 다시 학습시키면 된다.
기존 학습 알고리즘을 가지고 다시 학습하는 경우에 방법이 새로운 dataset에 따라서 두 가지의 방법이 있다.
만약, 방사선 이미지 dataset이 많지 않다면, 마지막 층의 파라미터만 초기화하고 나머지 layer의 파라미터는 고정시켜서 학습시킬 수 있다. 만약, 데이터가 충분히 많다면, 나머지 layer에 대해서도 다시 학습시킬 수 있다.
(경험상, dataset의 크기가 작다면 output layer만 다시 학습하거나, 마지막 2개 layer정도만 다시 학습시키는 것이 좋다.)
모든 layer의 파라미터를 다시 트레이닝시키는 경우에, 이미지 인식 기능에 대해서 첫번째 학습을 Pre-training이라고 부른다.(신경망의 파라미터를 pre-initialize or pre-training하기 위해서 이미지 인식 데이터를 사용하기 때문)
그리고, 방사선 이미지에 학습시키는 두번째 단계를 종종 fine tuning이라고 한다.
이렇게 이미지 인식 기능에서 학습한 내용을 방사선 이미지를 인식하고 진단하는 것으로 이양(transfer)시킨 것이다. 이것이 가능한 이유는 edges를 감지하거나, curve를 감지, 또는 positive objects를 감지하는 low level features(특성) 때문이다. 이미지 인식을 위한 데이터셋(고양이, 개 등)에서 이미지의 구조, 이미지가 어떻게 생겼는지에 대해서, 즉, 이미지들의 부분부분들을 인식하도록 학습한 것들이 (가지고 있는 방사선 이미지 dataset이 적더라도)방사선 이미지 인식에도 유용할 수 있다.
정리하자면, Transfer Learning은 Task A와 Task B가 같은 입력(이미지나 음성같은)으로 구성되어 있고, Task A의 데이터가 Task B의 데이터보다 훨씬 더 많은 경우에 가능하다. 조금 더 추가하자면, Task A에서 학습하는 low level 특성이 Task B를 학습하는데 도움이 될 수 있다고 판단되는 경우에 사용할 수 있다.
Multi-task Learning
Transfer Learning이 순차적으로 Task A를 학습하고 Task B로 넘어가는 절차가 있었다면, Multi-task Learning은 동시에 학습을 진행한다. NN이 여러가지 Task를 할 수 있도록 만들고, 각각의 Task가 다른 Task들을 도와주는 역할을 한다.
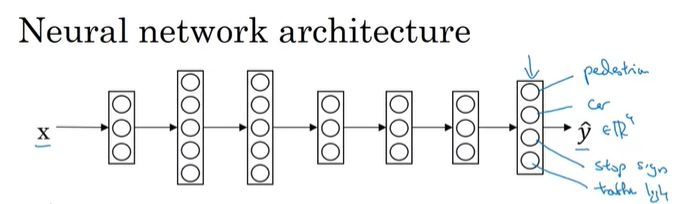
우리가 자율주행 자동차를 만든다고 생각해보자. 이런 자율주행 자동차는 보행자나 다른 차량, 정지 표지판, 신호등 등을 잘 감지해야 한다.
위 왼쪽 이미지를 보면, 정지 표지판과 차량이 있고, 보행자나 신호등은 보이지 않는다. 이 이미지가 inputx^{(i)}x(i)라고 한다면, outputy^{(i)}y(i)는 하나의 label이 아닌 4개의 label이 필요할 것이다. 만약 더 많은 것들을 감지하려고 한다면, 4개가 아니라 더 많은 label을 가질 수 있을 것이다.(여기서는 4개만 감지한다고 가정한다)
그러면y^{(i)}y(i)는 4x1 vector가 되고, dataset 전체를 참조하면, Y matrix는 오른쪽 아래처럼 4 x m matrix가 된다.
우리는 y값을 예측하기 위해서 NN을 학습시키는 것이고, inputxx를 가지고, output\hat{y}y^를 구하는게 목적이다.
위의 Neural Network를 학습하기 위해서는 NN의 Loss를 정의해야 한다.
예측값은 4x1 vector인\hat{y}y^이기 때문에, Loss는 다음과 같이 구할 수 있다.
그리고 Loss는 보통 Logistic Loss를 사용하고,\mathscr{L}(\hat{y}_j^{(i)}, y_j^{(i)}) = -y_j^{(i)}log(\hat{y}_j^{(i)}) - (1 - y_j^{(i)})log(1 - \hat{y}_j^{(i)})L(y^j(i),yj(i))=−yj(i)log(y^j(i))−(1−yj(i))log(1−y^j(i))이다.
여기서 이미지는 복수의 label을 가질 수 있다. 따라서, 우리는 이미지가 보행자나 자동차, 정지 표지판, 신호등으로 판단하는 것이 아니라, 하나의 이미지에 대해서 보행자, 차량, 정지 표지판, 신호등이 있는지 판단하는 것이기 때문에, 여러 개의 물체가 같은 이미지에 존재할 수 있다는 것이다. 여기서 결과는 4개의 label을 가지고, 이미지가 4개의 물체를 포함하고 있는지 알려주는 역할을 한다.
우리가 사용할 수 있는 또 다른 방법은 4개의 NN을 각각 트레이닝시키는 것이다. 하지만 NN의 초반 특성들 중의 일부가 다른 물체들과 공유될 수 있다면, 이렇게 4개의 NN을 각각 트레이닝시키는 것보다,한 개의 NN을 학습시켜서 4개의 일을 할 수 있도록 하는 것이 보통 더 좋은 성능을 갖는다.
부가적인 내용으로, 이제까지 학습을 하기 위한 데이터의 label이 모두 달려있는 것처럼 설명했지만, multi-task learning은 어떤 이미지가 일부 물체에 대해서만 label이 되어 있더라도 잘 동작한다.
위 레이블처럼 레이블하는 사람이 귀찮거나, 실수로 레이블하지 않았아서 물음표로 나타나더라도 알고리즘을 학습시킬 수 있다. 이런 경우에 Loss를 구할 때에는 물음표는 제외하고 y의 값이 0이거나 1인 것들만 취급해서 Loss를 구한다.
Multi-Tasking은 언제 사용할 수 있을까?
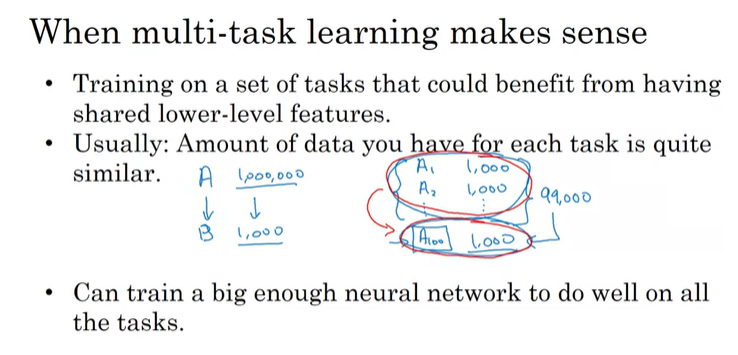
첫 번째로 각각의 task들을 학습할 때, lower-level 특성을 서로 공유해서 유용하게 사용될 수 있는 경우에 가능하다.
두 번째는 필수 규칙은 아니고, 항상 옳지도않지만, 각각의 task의 dataset의 양이 유사할 때 가능하다. 엄격하게 적용되는 것은 아니지만, multi-task learning이 효과가 있으려면, 보통 다른 task들의 data의 합이 하나의 task의 양보다 훨씬 많아야 한다.
마지막은, 충분히 큰 neural network에서 학습시키는 경우에 잘 동작한다. Rich Carona 연구원은 multi-task learning이 각각의 NN으로 학습하는 것보다 성능이 좋지 않다면, NN이 충분히 크기 못하는 경우라는 것을 발견했다.
실제로, multi-task learning은 transfer learning보다 훨씬 더 적게 사용되며, transfer learning의 경우에는 data는 적지만, 문제 해결을 위해 사용되는 경우를 자주 보게 된다.
예외적으로 computer vision object detection영역에서는 transfer learning보다 multi-task learning이 더 자주 사용되며, 개별적인 NN으로 학습하는 것보다 더 잘 동작한다.
What is End-to-end Deep Learning?
최근 개발된 것 중에 흥미로운 것 중 하나는 End-to-end deep learning의 발전이다. End-to-end deep learning은 여러 단계의 process를 거치는 것들을 하나의 NN으로 변환하는 것이다.
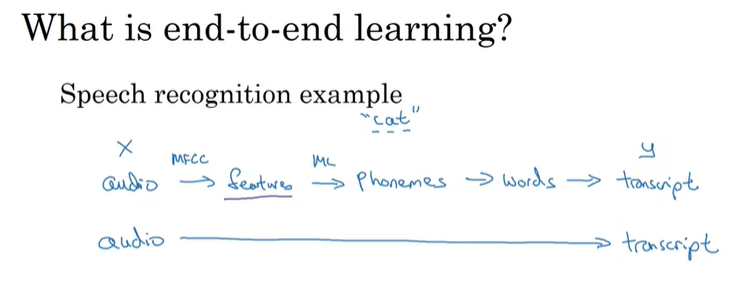
음성 인식을 예로 들어보면, input x인 오디오를 사용해서 output y에 매핑하면 오디오 클립이 글로 옮겨지게 되는 것이다. 이전에 음성 인식은 많은 단계가 필요했다. 먼저, 오디오의 hand-designed feature(사람이 직접 feature들을 지정)들을 추출한다. MFCC라는 알고리즘을 사용할 수 있는데, 이 알고리즘은 오디오의 hand-designed feature와 low-level feature를 추출하는 알고리즘이다. 그리고 머신러닝을 적용해서 Phonemes(음소; 소리의 기본단위)를 추출한다. 그런 다음에 음소들을 묶어서 words 형태로 만들고, 글로 나타낸다.
반대로 End-to-end deep learning은 하나의 거대한 Neural Network를 학습시켜서, 오디오 클립을 입력하고 다이렉트로 문자로 출력하도록 하는 것이다.
End-to-end learning이 효과를 나타내기 시작하면서, 많은 연구원들이 개별적인 단계를 설정하기 위해서 파이프라인을 설계하는 시간을 줄이게 되었다.
Whether to use End-to-end Deep Learning
장점
- 완벽한 학습을 통해서 데이터가 말을 하는 것처럼 할 수 있다. 우리가 충분히 많은 데이터를 가지고 있다면, X -> Y에 매핑되는 기능을 만들어낼 수 있다. 예를 들어, 이전의 음성 인식 시스템에서는 단어의 기본 음절 단위를 가지고(음성학) 해석을 하는데, 학습 알고리즘이 음성학적으로 생각하지 않고, 음성 표현이 바로 해석된다면, 전체적인 성과는 더 좋아질 것이다.
- 수작업이 줄어듬. 이 경우에는 워크플로우가 단순해지고, 중간 과정들을 설계하는데 많은 시간을 투자하지 않아도 된다.
단점
- 데이터가 많이 필요하다. X-Y 매핑을 바로 하기 위한 데이터가 필요하다. 이전 강의에서는 하위 작업인 얼굴 인식과 얼굴을 식별하기 위한 데이터들은 많았지만, 이미지를 바로 식별하기 위한 데이터는 거의 없었다. 그래서 이런 시스템을 훈련시키기 위해서는 입력과 출력이 모두 필요한 데이터가 필요하다.
- 유용하게 수작업으로 설계된 component들을 배제한다는 것이다. 데이터가 많지 않다면, train set으로 얻을 수 있는 것이 적고, 잘 설계된 hand-designed component를 사용하는 것이 더 좋은 성능을 낼 수 있다.
End-to-end deel learning을 적용하기 위해서 중요한 질문은, x -> y로 매핑시키기 위해 필요한 데이터가 충분히 많은가의 여부이다. 이전 강의에서 봤듯이, 뼈를 인식하는 것과 인식 뼈를 토대로 나이를 추정하는 것은 데이터가 많이 필요하지 않을 수 있지만, 뼈 사진을 통해서 바로 나이를 매핑하는 것은 복잡한 문제처럼 보이고, 많은 데이터가 필요할 것이다.
정규화&표준화가 필요한 이유는 기준을 설정하고 그 기준내에서 각 데이터들을 평가하기 때문에 비교가 편하다는 것
머신러닝을 하다보면 기본적으로 많은 양의 데이터를 처리하게 된다. 그리고 그 데이터안에 target과 관련있는 특성(feature)을 뽑아낸다.
예를 들어, 오늘 입을 옷을 결정할 때 그날의 온도, 습도, 날씨, 약속의 유무 등을 따지는 것과 같다. 그럼 온도, 습도, 날씨는 ℃, F 등특성의 단위도 다르고 그 범위도 달라 직접적으로 비교할 수 없다. 내가 토익(990만점) 400점이고, 넌 영어(100점만점) 90점이니까 내가 더 공부를 잘하네? 라고 할 수 없는 듯이 말이다.
그래서각 특성들의 단위를 무시하고 값으로 단순 비교할 수 있게만들어 줄 필요가 있다. 그것이 우리가 정규화/표준화를 진행하는 이유다. 정규화/표준화가 해주는 것을특성 스케일링(feature scaling)또는데이터 스케일링(data scaling)이라고 한다.
또한 가장 중요한 이유는scale의 범위가 너무 크면 노이즈 데이터가 생성되거나 overfitting이 될 가능성이 높아지기 때문이다.
딥러닝 관점 직관적 이해
아래와 같이Unnormalized된 상태에서는Learning Rate을 매우 작게 설정해야 정상적을 학습이 된다. 이유는 cost 그래프가elongated하기 때문이다. 따라서elongated contour의 모습을 가진다. 아래와 같이Input의 Range가 서로 다르다면Gradient Descent Algorithm을 적용하는것이 매우 까다로워지는 상황이 발생 한다.
하지만normalization을 적용하면 좀 더spherical contour를 가지게 된다. 이렇게 하면 좀 더Gradient Descent Algorithm으로쉽게그리고빠르게최적화 지점을 찾게 된다.
배치의 사전적 의미는 (일괄적으로 처리되는)집단이다. 배치는 한번에 여러개의 데이터를 묶어서 입력하는 것인데, GPU 의 병렬 연산 기능을 최대한 효율적으로 사용하기 위해 쓰는 방법이다.(GPU 의 병렬연산에 대한 설명 링크)
배치는 Iteration 1회당 사용되는 training data set 의 묶음이며, Iteration 은 정해진 batch size 를 사용하여 학습(forward - backward) 를 반복하는 횟수를 말한다.
Batch gradient descent(BGD)
전체 데이터 셋에 대한 에러를 구한 뒤 기울기를 한번만 계산하여 모델의 parameter 를 업데이트 하는 방법.
이름에 들어가는 Batch 때문에 혼동스러울 수도 있다.(Ian Goodfellow 또한 자신의 책에서 그렇게 말한다.) 여기서 말하는 batch 는 말 그대로 total training dataset 을 의미한다. 데이터를 분할해서 다룰 때 사용하는 'batch' 라는 단어는 엄밀히 'mini-batch'를 의미하지면 편의상 batch 와 혼용해서 사용하는 것.
처음엔 '한 개의 데이터마다 한 개의 기울기를 구할 수 있는데, 어떻게 전체 데이터 셋에 대해서 기울기를 한번만 구한다는 것인가?' 라는 의문을 가지며 BGD를 잘못 이해하고 있었다.
Gradient descent 라는 알고리즘 자체는 loss function 을 입력 데이터 x 에 대해 편미분해서 기울기를 계산하는 것이 아닌, 가중치 w 에 대해서 편미분을 하는 것이기 때문에, 기울기를 계산하는 것 자체는 입력 데이터 x 의 갯수와 상관이 없다.
에러값을 전체 데이터에 대한 loss function 의 합으로 정의하던 평균으로 정의하던 단순히 w 에 대한 편미분을 수행하면 되는 것.
BGD의 장점
● 전체 데이터에 대해 업데이트가 한번에 이루어지기 때문에 후술할 SGD 보다 업데이트 횟수가 적다. 따라서 전체적인 계산 횟수는 적다.
● 전체 데이터에 대해 error gradient 를 계산하기 때문에 optimal 로의 수렴이 안정적으로 진행된다.
● 병렬 처리에 유리하다.
BGD의 단점
● 한 스텝에 모든 학습 데이터 셋을 사용하므로 학습이 오래 걸린다.
● 전체 학습 데이터에 대한 error 를 모델의 업데이트가 이루어지기 전까지 축적해야 하므로 더 많은 메모리가 필요하다.
● local optimal 상태가 되면 빠져나오기 힘듦(SGD 에서 설명하겠음.)
Stochastic gradient descent(SGD)
추출된 데이터 한 개에 대해서 error gradient 를 계산하고, Gradient descent 알고리즘을 적용하는 방법.
모델의 레이어 층은 하나의 행렬곱으로 생각할 수 있고, 여러개의 묶음 데이터는 행렬이라고 생각 할 수 있다.
즉, 여러개의 묶음 데이터를 특정 레이어 층에 입력하는 것은 행렬 x 행렬로 이해할 수 있는데,
SGD는 입력 데이터 한 개만을 사용하기 때문에 한 개의 데이터를 '벡터' 로 표현하여 특정 레이어 층에 입력하는 것으로 이해할 수 있고 이는 벡터 x 행렬 연산이 된다.
SGD의 장점
● 위 그림에서 보이듯이 Shooting 이 일어나기 때문에 local optimal 에 빠질 리스크가 적다.
● step 에 걸리는 시간이 짧기 때문에 수렴속도가 상대적으로 빠르다.
SGD의 단점
● global optimal 을 찾지 못 할 가능성이 있다.
● 데이터를 한개씩 처리하기 때문에 GPU의 성능을 전부 활용할 수 없다.
Mini-batch gradient descent(MSGD)
엄밀히 따지면 MSGD 와 SGD 는 다른 알고리즘이지만 요즘엔 MSGD를 그냥 SGD라고 많이들 혼용해서 부른다. 그래서 Ian Goodfellow 책에서도 아래 그림처럼 MSGD 알고리즘을 설명할 때 SGD 라고 표현하고 있다.
출처: Deep Learning, Ian Goodfellow, Chap 8. 291pp.
위 알고리즘을 그림으로 간단하게 풀어서 설명하면 아래와 같다.
간단하게 그리다 보니 그림에 도형 갯수는 정확하지 않다. 어쨌든 전체 데이터셋에서 뽑은 Mini-batch 안의 데이터 m 개에 대해서 각 데이터에 대한 기울기를 m 개 구한 뒤, 그것의 평균 기울기를 통해 모델을 업데이트 하는 방법이다.
다시 간단하게 요약하면, BGD 와 SGD 의 장점만 빼먹고 싶은 알고리즘. 전체 데이터 셋을 여러개의 mini-batch 로 나누어, 한 개의 mini-batch 마다 기울기를 구하고 모델을 업데이트 하는 것.
예를들어, 전체 데이터가 1000개인데 batch size 를 10으로 하면 100개의 mini-batch 가 생성되는 것으로, 이 경우 100 iteration 동안 모델이 업데이트 되며 1 epoch 이 끝난다.
MSGD의 장점
● BGD보다 local optimal 에 빠질 리스크가 적다.
● SGD보다 병렬처리에 유리하다.
● 전체 학습데이터가 아닌 일부분의 학습데이터만 사용하기 때문에 메모리 사용이 BGD 보다 적다.
MSGD의 단점
● batch size(mini-batch size) 를 설정해야 한다.
● 에러에 대한 정보를 mini-batch 크기 만큼 축적해서 계산해야 하기 때문에 SGD 보다 메모리 사용이 높다.
batch size 또한 hyper parameter 로써 사용자가 직접 설정해야 하는 값이다. batch size 는 보통 2의 제곱수를 이용하는데, 많은 벡터 계산이 2의 제곱수가 입력될 때 빠르기 때문이다.
지수 가중 이동평균은 경사하강법 및 미니배치 경사하강법보다 효율적인 알고리즘을 이해하기위해 알아야하는 개념입니다. 이 개념은 최근 데이터에 더 많은 영향을 받는 데이터들의 평균 흐름을 계산하기 위한 것으로 최근 데이터에 더 높은 가중치를 줍니다. 수식으로 알아보겠습니다.
여기서vt는t번째 데이터의 가중 지수가중이동평균입니다. 그리고β값은 하이퍼파라미터로 최적의 값을 찾아야하는데 보통은 0.9를 많이 사용합니다. 마지막으로θt는t번째 데이터의 값입니다. 그럼 먼저β값을 변경해보면서 이 수식에 대한 이해를 해보겠습니다.
우선,β가 0.9일 경우를 보겠습니다. 사실 이 때의vt는 이전 10개의 데이터의 평균과 거의 같습니다. 이는 아래 식으로 계산해낼 수 있습니다.
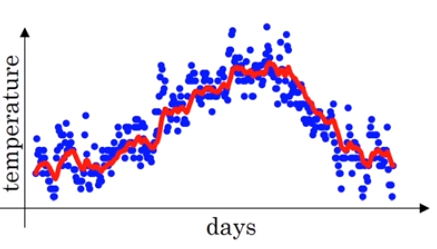
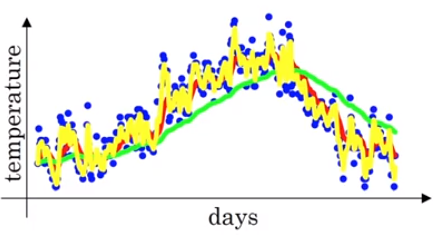
우선 지금은β에 따른 지수가중이동평균값을 이해하기위해 위 식이 성립하는 이유는 나중에 언급하겠습니다. 다시 돌아와서β가 0.9일때 지수가중이동평균 그래프는 다음과 같이 그려집니다. 아래 붉은선 그래프는 일년동안의 기온변화를 지수가중이동평균으로 나타낸 그래프입니다.
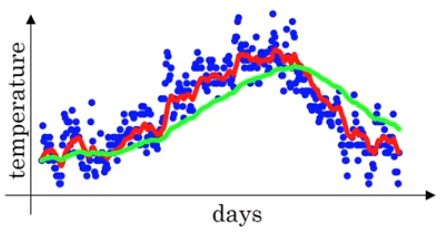
위와 같이β가 0.98일때, 0.9일때보다 완만하고 부드러운 곡선인 이유는 1/(1-0.98)의 값이 50이므로 위 녹색 그래프는 50개 데이터의 평균값으로 만들어지기 때문입니다. 더 많은 데이터의 평균값을 이용하기 때문에 곡선이 더 부드러워 집니다. 이는 원래의 데이터의 값과 더 멀어진다고도 할 수 있습니다. 더 큰 범위 데이터에서 평균 낸 값이기 때문입니다. 여기서 내릴 수 있는 결론은β값이 클수록 선이 더 부드러워진다는 것입니다. 그렇다면β를 0.5로 낮춘다면 어떤 그래프가 그려질까요? 그래프를 그리기 이전에 어떻게 그려질지 예측할 수 있을 것입니다.
1/(1-0.5)의 값이 2이므로 2개의 데이터의 평균값으로 그래프가 그려집니다. 오직 2개의 데이터만 이용하므로 노이즈가 심하고 민감한 그래프가 그려지는 것입니다.
그럼 이제 처음에 봤던 지수가중이동평균 식을 상세하게 분석해 보겠습니다.
설명을 편하게 하기위해서vtvt의 순서를 역순으로 했습니다. 맨 위에v100v100에 대한 식은v99v99를 대체해주므로써 아래와 같이 표현할 수 있습니다.
그리고 위 식의v98v98을 또 다음과 같이 대체할 수 있습니다.
반복적으로v값을 대체해준 후 풀어쓰면 아래와 같은 식이 나오지요.
마지막 식을 통해서 규칙성을 파악하셨겠지만vt는 이전 데이터에 지수적으로 감소하는 함수를 곱해주고 모두 더해주는 것입니다.θ앞의 계수들을 모두 더하면 1 또는 1에 가까운 값이 됩니다. 이는 아래서 자세히 설명드릴편향보정이라고 불리는 값 입니다. 이 값들에 의해 지수가중평균이 되는 것입니다. 그럼vt가 얼마나 많은 데이터의 평균값이 되는지 궁금하실 겁니다. 위 예시에서 사용한β값인 0.9의 10거듭제곱 값은 대략적으로 0.35와 같습니다. 이는1e값과도 대략적으로 같습니다. 일반적으로 표현하자면
즉,1e값이 되기까지 이전 10개의 데이터가 필요한 것입니다. 이를 한 눈에 이해하기 위해서 아래 그림을 확인해 보겠습니다.
위 그림과 같이 10개 이전의 데이터의 가중치가 현재 가중치의 약 1/3로 줄어드는 것입니다. 이전에 예시로 들었던ββ값인 0.98의 경우0.98^50이 대략적으로1e와 같습니다. 이는 이전에 언급했던11−β11−β를 관습적으로 쓰는 이유입니다.1/(1−0.98)=501/(1−0.98)=50이기 때문이지요.
실제로 구현할 때는v0,v1,v2,...v0,v1,v2,...을 모두 변수화 하지 않습니다. 아래와 같이vθ값을 덮어씌워 줍니다. (vθ로 표시한 이유는θ를 매개변수로 하는 지수가중이동평균을 계산한다는 것을 나타내기 위함입니다.)
이렇게vθ는 매번 업데이트 됩니다. 이렇게 지수평균값을 얻는 장점은 아주 적은 메모리를 사용한다는 점입니다. 가장 최근에 얻은 값을 계속 덮어쓰기만 하면 되니까요. 이 방법은 컴퓨터 계산비용과 메모리 효율 측면에서 더 효율적이기 때문에 오늘날 머신러닝에서 많이 사용하고 있습니다.
Training Set, Dev Set, Test Set을 잘 설정하면 좋은 성능을 갖는 NN을 빨리 찾는데 도움이 될 수 있다.
NN에서는 다음과 같이 결정해야 할 것들이 있다.
- # of layer
- # of hidden unit
- Learning Rate
- Activation Function
처음 새롭게 NN을 구현할 때에는 적절한 하이퍼 파라미터 값들을 바로 선택하기는 거의 불가능하다. 그래서, 반복적인 과정을 통해 실험하면서 하이퍼 파라미터 값들을 바꿔가며 더 좋은 성능을 갖는 NN을 찾아야 한다.
Applied ML is a highly iteration process
경험이 많은 딥러닝 개발자들도 적절한 파라미터를 한 번에 선택하는 것은 거의 불가능하다. 그래서 오늘날 적용된 딥러닝은 반복적인 과정을 통해서 실험하면서 더 좋은 신경망을 찾아간다. 여기서 중요한 것은 우리가 이 반복적인 과정을 얼마나 효율적으로 하느냐이다.
여기서 우리는 데이터를Train/Dev/Test Set를 적절하게 설정하면 훨씬 효율적으로 수행할 수 있다.
[Bias / Variance]
Bias
Bias(편향)는 예측값과 실제값의 차이이다.
즉, Bias(편향)가 크다는 것은, 예측값과 실제값의 차이가 크다는 것이며, 이는 과소적합을 의미한다.
Variance
Variance(분산)는 입력에 따른 예측값의 변동성을 의미한다.
즉, Variance(분산)가 크다는 것은, 입력에 따른 예측값의 변동성이 크다는 것이며, 이는 과대적합을 의미한다.
Trade-off
Trade-off는 시소처럼 한쪽이 올라가면 한쪽이 내려가는 관계를 의미한다.
예제 1
파란 점이 예측값, 빨간 원이 실제값을 의미한다.
Bias가 높다는 것은, 예측값과 실제값의 오차가 크다는 것을 의미한다. (과소적합 상황)
Variance가 높다는 것은, 예측값의 변동성이 크다는 것을 의미한다. (과대적합 상황)
예제 2
왼쪽 그래프는 큰 bias, 작은 variance
오른쪽 그래프는 작은 bias, 큰 variance
왼쪽 그래프의 예측 값, 실제 값이 차이는 오른쪽 그래프보다 크다. (큰 bias)
오른쪽 그래프의 예측 값, 실제 값의 차이는 0이다. (작은 bias)
왼쪽 그래프는 일반화가 잘 되어 있기 때문에 예측 값이 일정한 패턴을 나타낸다. (작은 variance)
오른쪽 그래프는 예측 값이 일정한 패턴 없이 들쑥날쑥하다. (큰 variance)
예제 3
모델을 학습을 시킬수록 모델의 복잡도는 더 올라간다.
이를 X축 모델 복잡도(model complexity)로 표현하면,
모델이 단순해질수록, Bias는 증가하고 Variance는 감소한다. (과소적합 상황)
모델이 복잡해질수록, Bias는 감소하고 Variance는 증가한다. (과대적합 상황)
결국, 전체 Error는 Bias와 Variance 간의 Trade-off 관계 때문에, 계속 학습 시킨다고 해도 쉽게 줄어든지 않는다.
즉, 무조건 Bias만 줄일 수도, 무조건 Variance만 줄일 수도 없기 때문에, Bias와 Variance의 합이 최소가 되는 적당한 지점을 찾아 최적의 모델을 만들어야한다.
[Regularization]
먼저 L1 Regularization 과 L2 Regularization 을 설명
결론부터 얘기하자면 L1 Regularization 과 L2 Regularization 모두 Overfitting(과적합) 을 막기 위해 사용됩니다.
위 두 개념을 이해하기 위해 필요한 개념들부터 먼저 설명하겠습니다.
글의 순서는 아래와 같습니다.
Norm
L1 Norm
L2 Norm
L1 Norm 과 L2 Norm 의 차이
L1 Loss
L2 Loss
L1 Loss, L2 Loss 의 차이
Regularization
L1 Regularization
L2 Regularization
L1 Regularization, L2 Regularization 의 차이와 선택 기준
Norm
Norm 은 벡터의 크기를 측정하는 방법입니다.
두 벡터 사이의 거리를 측정하는 방법이기도 합니다.
여기서 p 는 Norm 의 차수를 의미합니다.
p = 1 이면 L1 Norm 이고, P = 2 이면 L2 Norm 입니다.
n은 해당 벡터의 원소 수 입니다.
L1 Norm
L1 Norm 은 벡터 p, q 의 각 원소들의 차이의 절대값의 합입니다.
예를 들어, 두 벡터 p =(3, 1, -3), q = (5, 0, 7) 의 L1 Norm을 구한다면
|3-5| + |1-0| + |-3 -7| = 2 + 1 + 10 = 13 이 됩니다.
L2 Norm
L2 Norm 은 벡터 p, q 의 유클리디안 거리(직선 거리) 입니다.
여기서 q 가 원점이라면, 벡터 p, q의 L2 Norm 은 벡터 p와 원점 간의 직선거리라고 할 수 있습니다.
예를 들어, 두 벡터 p =(3, 1, -3), q = (0, 0, 0) 의 L2 Norm 을 구한다면
3^2 + 1^2 + (-3)^2 = 19 가 됩니다.
L1 Norm과 L2 Norm 의 차이
검정색 두 점사이의 L1 Norm 은 빨간색, 파란색, 노란색 선으로 표현 될 수 있고
L2 Norm 은 오직 초록색 선으로만 표현될 수 있습니다.
L1 Norm 은 여러가지 path 를 가지지만 L2 Norm 은 Unique shortest path 를 가집니다.
예를 들어 p = (1, 0), q = (0, 0) 일 때 L1 Norm = 1, L2 Norm = 1 로 값은 같지만 여전히 Unique shortest path 라고 할 수 있습니다.
L1 Loss
y_i 는 실제값을, f(x_i)는 예측값을 의미합니다.
실제값과 예측값 사이의 오차의 절대값을 구하고, 그 오차들의 합을 L1 Loss 라고 합니다.
이를 Least absolute deviations(LAD), Least absolute Errors(LAE), Least absolute value(LAV), Least absolute residual(LAR), Sum of absolute deviations 라고 부릅니다.
L2 Loss
L2 Loss 는 오차의 제곱의 합으로 정의됩니다.
이를 Least squares error(LSE) 라고 부릅니다.
L1 Loss, L2 Loss 의 차이
L2 Loss 는 직관적으로 오차의 제곱을 더하기 때문에 Outlier 에 더 큰 영향을 받습니다.
"L1 Loss 가 L2 Loss 에 비해 Outlier 에 대하여 더 Robust(덜 민감 혹은 둔감) 하다." 라고 표현 할 수 있습니다.
Outlier 가 적당히 무시되길 원한다면 L1 Loss 를 사용하고
Outlier 의 등장에 신경써야 하는 경우라면 L2 Loss 를 사용하는 것이 좋겠습니다.
L1 Loss 는 0인 지점에서 미분이 불가능하다는 단점 또한 가지고 있습니다.
Regularization
보통 번역은 '정규화' 라고 하지만 '일반화' 라고 하는 것이 이해에는 더 도움이 될 수도 있습니다.
모델 복잡도에 대한 패널티로, 정규화는 Overfitting 을 예방하고 Generalization(일반화) 성능을 높이는데 도움을 줍니다.
Regularization 방법으로는 L1 Regularization, L2 Regularization, Dropout, Early stopping 등이 있습니다.
model 을 쉽게 만드는 방법은 단순하게 cost function 값이 작아지는 방향으로 진행하는 것입니다.
하지만, 이럴 경우 특정 가중치가 너무 큰 값을 가지게 될수도 있습니다.
가중치가 큰 값을 가진다는 것은 모델의 일반화 성능이 떨어진다는 것을 의미합니다. (과대적합)
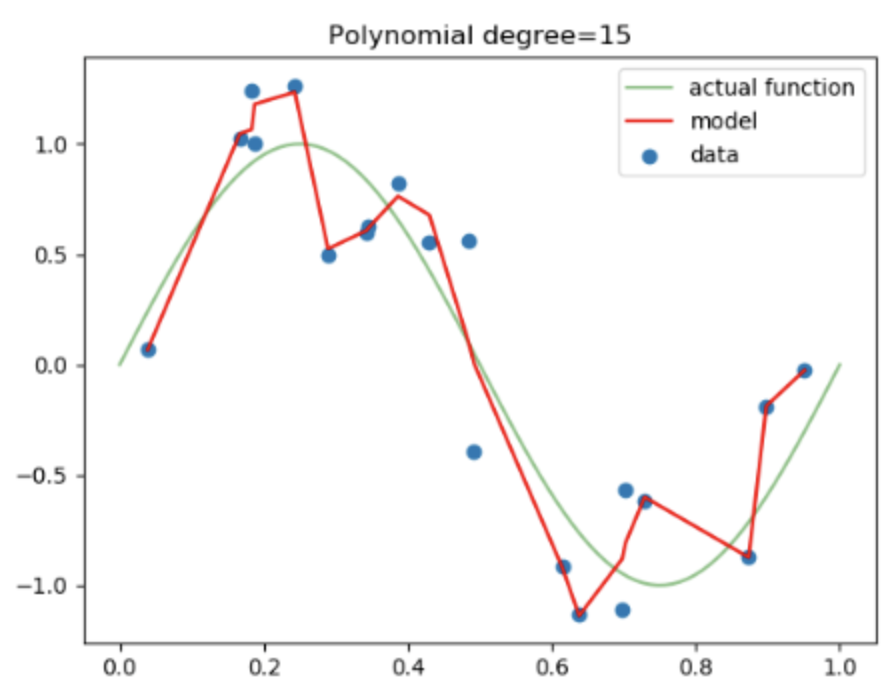
위 그래프에서 actual function 이 target function 이라고 했을 때, model 이 데이터에 overfitting 된 것을 알 수 있습니다.
따라서, 위 그래프처럼 모델에 Regularization 을 적용한다면, 특정 가중치가 너무 과도하게 커지지 않게 됩니다.
L1 Regularization
L1 Regularization을 사용해 새롭게 정의된 cost function
논문에 따라서 가중치의 절대값 앞에 분수로 붙는 1/n 이나 1/2 가 달라지는 경우가 있는데
L1 Regularization 의 개념에서 가장 중요한 것은 cost function 에 가중치의 절대값을 더해준다는 것이기 때문에
1/n 이나 1/2 가 달라지는 경우는 연구의 case 에 따라 다르다고 이해하고 넘어가겠습니다. (이는 L2 Regularization 또한 같습니다).
기존의 cost function 에 가중치(W)의 크기가 포함되면서,
학습의 방향이 단순하게 cost function의 값이 작아지는 방향으로만 진행되는 것이 아니라,
가중치(W) 또한 작아지는 방향으로 학습이 진행됩니다.
이때 λ 는 상수로 0에 가까울 수록 정규화의 효과는 없어집니다.
새롭게 정의된 cost function을 w에 대해 편미분한 결과
w의 크기와 상관없이 w의 부호에 따라 상수값을 빼주는 방식
L1 Regularization 을 사용하는 Regression model 을Least Absolute Shrinkage and Selection Operater(Lasso) Regression이라고 부릅니다.
L2 Regularization
L2 Regularization을 사용해 새롭게 정의된 cost function
기존의 cost function 에 가중치의 제곱을 더함으로써
L1 Regularization 과 마찬가지로 가중치가 너무 크지 않은 방향으로 학습되게 됩니다.
새롭게 정의된 cost function을 w에 대해 편미분한 결과
w 에 ( 1-nλ/n ) 을 곱함으로써 w 값이 작아지는 방향으로 진행
이를 Weight decay라고 함
L2 Regularization 을 사용하는 Regression model 을Ridge Regression이라고 부릅니다.
L1 Regularization, L2 Regularization 의 차이와 선택 기준
L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행됩니다.
때문에 작은 가중치들은 거의 0으로 수렴 되어, 몇개의 중요한 가중치들만 남게 됩니다.
그러므로 몇 개의 의미 있는 값을 끄집어내고 싶은 sparse model 같은 경우에는 L1 Regularization이 효과적입니다.
다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요합니다.
L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미칩니다.
따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적입니다.
[Gradient Checking]
Gradinet checking은 Forward propagation, Backward propagation 이후, backward propagation으로 구해진역전파값이 정확한지 점검하는 과정이다.
학습 단계에서 사용하는 것이 아니라디버깅 단계에서 사용한다. 왜냐하면, 한 번 학습할 때마다 Gradient checking할 경우 시간이 너무 오래 소요되기 때문이다.
수식으로 정의된 Derivative(혹은 Gradient)값과 Backward progation으로 구해진 값이 동일하거나 근소한 차이를 보이는지 확인한다.
구체적으로, delta에 속하는 여러가지 파라미터들(W,b...)들을 각 레이어에 속한 각 뉴런값들을 n by 1차원의 메트릭스로 표현한다. (n=전체 모델이 학습시켜야 하는 파라미터의 총 개수)
여러 파라미터의 각 값의 grad, gradapprox, grad-gradapprox의 노름값을 numpy의np.linalg.norm함수를 사용하여 구한다.
만약, gradient checking시 문제가 생겼다면, 순차적으로 레이어를 훑으면서 어느 값이 잘못되었는 찾아본다.
Regularization을 적용하였을 때, 이 부분을 반영하여 gradient checking해야 한다.
Drop-out을 적용하여 학습했을 때에는 Gradient checking을 실행할 수 없다. Dropout을 끈 상태에서 Gradient checking을 먼저 해보고, 이상이 없다면 drop-out시에도 이상이 없는 것으로 편의상 간주한다.