Carrying Out Error Analysis
dev set에서 모델 분석 결과 잘못 표기된 예시를 찾고 잘못 표기된 예시에서 거짓 양성과 거짓 음성을 찾습니다. 그 후 다양한 카테고리에 대한 오류의 총 개수를 각각 카테고리 별로 찾아 냅니다.
이렇게 수작업으로 분석하는 것은 시간이 꽤 긴 시간이 소요되는데, 그럼에도 불구하고 우리가 해야되는 것들 중에서 우선순위를 정하는데 많은 도움을 주고, 접근 방법에 대한 효율을 수치적으로 측정할 수 있다.
Cleaning Up Incorrectly Labeled Data
우선 training set에서 고려해보면, 딥러닝 알고리즘은 training set에서 random error에 대해서 상당히 견고하다는 것이 밝혀져있다. 따라서, 이렇게 잘못 레이블된 example들이 고의적으로 발생한 것이 아니라, 단순 실수에 의한 것이고 랜덤으로 발생되었다고 한다면, 이 error는 그대로 두어도 괜찮고, 고치는데 많은 시간을 쏟을 필요가 없다.
, 딥러닝 알고리즘은 systemic errors에 대해서는 문제가 발생할 수 있다. 예를 들어서, dataset의 레이블을 담당하는 사람이 지속적으로 흰색 강아지를 고양이로 레이블했다면, 분류기가 모든 흰색 강아지를 고양이로 분류하도록 배울 수 있기 때문에 문제가 될 수 있다.
만약 dev set이나 test set에서 잘못 레이블된 example들이 있다면 어떨까?
이런 문제가 우려스럽다면, 추천하는 방법은 Error Analysis를 진행하면서, 카테고리를 추가해서 잘못 레이블된 example의 %를 구하는 것이다.
(가끔 잘못 레이블된 example들을 살펴보면, 학습 알고리즘이 잘못 분류한 것이 아니라, 데이터를 레이블한 사람이 미처 뒷배경에 있는 고양이를 보지 못하고 잘못 레이블한 경우도 있을 수 있다.)

그렇게 잘못 레이블된 example의 %를 구한다. 그리고 이 문제를 개선해서 dev set에서 알고리즘의 성능이 현저하게 개선될 수 있다면 레이블이 잘못된 것을 수정하라고 이야기할 수 있지만, 그 성능이 크게 바뀌지 않는다면 효율적이지 않다.
전체적인 dev set error를 살펴보고 결정하는 것을 추천한다. 이전 예제처럼 10%의 dev error를 가지고 있고, 잘못 레이블된 이미지를 수정해서 개선한다면 10% error 중에서 6%, 즉, 0.6%를 개선할 수 있다는 것이다. 따라서 레이블을 수정한다고 해도 9.4%까지밖에 성능이 개선되지 않는다는 것이고, 이는 매우 비중이 작다고 볼 수 있다.
만약 잘못 레이블된 example의 비율이 30%이고, dev error가 2%라면, error의 30%는 0.6%이고, 레이블을 수정하면 error를 1.4%까지 줄일 수 있기 때문에 꽤 비중이 높다고 할 수 있고, 시도할만한 방법이라고 할 수 있다.
Build your First System Quickly, then Iterate
- Set up dev/test set and metric
- Build initial system quickly
- Use Bias/Variance anylysis & Error analysis to priority next steps.
구체적으로 우선 dev/test set과 metric을 설정하는 것이다. 결국에는 목표를 어디에 둘지 설정하는 과정이다. 만약 잘못된 경우에는 언제든지 변경할 수 있다. 일단, 목표를 설정하고, 그 다음에 머신러닝 시스템을 우선 만든다. traing set를 수집하고, 학습한 다음 결과를 살펴본다. 그리고 dev/test set과 metric을 통해서 얼마나 잘 동작하는지 살펴보고 이해하는 것이다. 그런 다음에 Bias/Variance analysis나 Error analysis를 사용해서 다음 단계에 대한 우선순위를 지정해서 개선할 수 있다.
요약하자면, 초기 시스템으로 우선 학습을 완료하고, 학습 완료된 시스템을 통해 bias/variance를 조절하고, error analysis를 통해서 error를 살펴보고 많은 접근 방법 중에서 우선순위를 정해서 다음 과정을 진행하는 것을 반복하라는 것이다.
Training and Testing on Different Distributions
핵심은 dev/test set은 우리가 중점적으로 집중해야하는 데이터 분포도를 갖도록 하는 것이다. 즉 예를 들어, 모바일 앱에서 업로드된 사진을 분류하는 것이 목적이기 때문에, dev/test set의 분포도를 모바일 앱을 통한 이미지 분포도를 갖도록 하는 것이다. 하지만, 여전히 training data와 dev/test set의 분포도는 서로 다르다. 그러나 이렇게 나누어진 데이터에서의 결과가 장기적으로 훨씬 더 좋은 성과를 보인다.
Bias and Variance with Mismatched Data Distributions
학습 알고리즘의 bias와 variance를 추정하는 것은 다음 스텝으로 어떤 업무를 수행해야할 지에 대한 우선순위를 결정하는데 큰 도움을 준다. 하지만, 학습 알고리즘의 training set과 dev/test set이 서로 다른 분포도를 가지고 있다면 bias/variance를 분석하는 방법이 달라진다.
training-dev set은 training set에서 일부 추출한 데이터인데, training set과 동일한 분포도를 가지게 되지만, 이 데이터는 학습을 위한 데이터는 아니다.
위와 같이 데이터를 분배하게 되고, train과 train-dev는 서로 같은 분포도를 갖고, dev와 test가 서로 같은 분포도를 갖는다. 물론 train/train-dev와 dev/test의 분포도는 서로 다르다.
이렇게 분배한 후에, training set으로만 학습시키고, Error Analysis를 진행하기 위해서, training error, training-dev error, dev error를 구한다.
위 두가지 예시를 살펴보자.
왼쪽 예시는 training error가 1%, training-dev error가 9%, dev error가 10%이다. 결과를 보면 training -> training-dev error에서 많이 증가한 것을 볼 수 있고, 같은 분포도를 갖더라도 일반화가 잘 되지 않았다는 것을 볼 수 있기 때문에, 이 문제는 variance 문제가 있다고 볼 수 있을 것이다.
오른쪽 예시는 training error는 1%, training-dev error는 1.5%, dev error는 10%이다. 이 경우에는 training과 training-dev error의 차이가 크지 않으므로, low variance를 갖는다고 할 수 있으며, dev error에서 많이 증가한다. 이런 경우가 전형적인 data mismatch문제를 갖고 있다고 할 수 있다.
다음 두가지 예시를 더 살펴보자.
이번에는 human error까지 포함했는데, 왼쪽 예시는 human error가 0%, training error는 10%, training-dev error가 11%, dev error가 12%이다. bayes error가 0%라는 의미인데, training error와의 차이인 avoidable bias가 매우 큰 것을 볼 수 있고, bias 문제가 있다고 볼 수 있다.(high bias setting을 가지고 있음)
오른쪽 예시는 동일하게 human error가 0%, training error 10%, training-dev error 11%, 그리고 dev error가 20%이다. 이 경우에는 두 가지의 문제점이 존재한다. 첫 번째로 bayes error와 training error의 차이가 크기 때문에 avoidable bias문제가 존재하고, 두 번째는 training-dev error와 dev error의 차이가 크기 때문에 data mismatch의 문제도 있다고 볼 수 있다.
핵심은 human-level error, training error, training-dev error, dev error를 확인하고, 이 오류들의 차이를 분석해서 avoidable bias problem이나 variance, mismatch문제가 있는지 확인하는 것이다.
Addressing Data Mismatch
Error Analysis로 mismatch문제가 있다는 것을 알았을 때, 위와 같은 방법이 있다.
첫 번째로는 training set과 dev/test set이 어떤 차이가 있는지 수작업으로 error analysis를 수행하는 것이다. test set에 overfitting하는 것을 피하려면, dev set에서만 error analysis를 수행해야 한다.
예를 들어서, 백미러 음성인식 시스템을 개발하고 있다면, training set과 dev set을 비교해서 dev set이 보통 소음이 더 심하고, 자동차 소음도 많다는 점을 발견할 수도 있다. 이처럼 training set이 dev set과 어떻게 다른지 파악할 수 있다면, 이후에 traininig data를 dev set과 더 유사하게 만들 수 있는 방법을 찾을 수 있다.
두 번째 방법은 dev/test set과 유사한 데이터를 만들거나 또는 수집하는 것이다. 자동차 소음이 가장 큰 원인이라고 발견했다면, 차량 내에서 소음이 심한 데이터를 학습할 수 있다.
이렇게 분석을 해서 결국 training data를 dev set와 더 유사하게 만드는 것이 목표라면 우리가 할 수 있는 방법은 무엇이 있을까? 우리가 사용할 수 있는 방법 중에 하나는 인공적으로 데이터를 합성하는 것이 있다.(Artificial data synthesis)
하지만, 이 방법을 사용할 때 한가지 주의할 점이 있다. 만약 우리가 10,000시간 동안 소음없이 깨끗하게 녹음된 데이터가 있고, 자동차 소음 데이터가 1시간짜리가 있다면, 자동차 소음 데이터를 10,000번 반복시켜서 합성할 수 있다. 실제 차량에서는 다양한 소음들이 있지만, 이 경우에는 우리가 1시간짜리 소음에 대해서만 학습을 진행하게 된다면, 한 시간짜리 자동차 소음에 overfitting할 수도 있다. 10,000시간 동안의 자동차 소음을 수집하는 것이 가능할지는 모르겠지만, 1만 시간의 자동차 소음으로 합성을 한다면 더 좋은 성능을 낼 수 있을 것이다.
즉, 합성을 통해서 만든 데이터들이 단지 전체의 일부분이 될 수도 있다는 것이다. 따라서 합성한 데이터에 overfitting할 위험이 존재하고, 합성할 때에 이 부분을 유의해야 한다.
Transfer Learning
딥러닝의 강력함은 한 가지 Task에서 학습한 내용은 다른 Task에 적용을 할 수 있다는 것이다. 예를 들어서, Neural Network(NN)이 고양이와 같은 사진을 인식하도록 학습했을 때, 여기서 학습한 것을 가지고 부분적으로 X-ray 이미지를 인식하는데 도움이 되도록 할 수 있다. 이것이 바로 Transfer Learning이라고 한다.
이미지 인식 기능을 NN으로 학습을 했다고 해보자. x는 이미지이고, y는 some object(인식 결과)이다. 이미지는 고양이나, 개, 또는 새 등이 될 수 있다. 이렇게 학습한 NN을 사용해서 transfer한다고 표현하는데, 고양이와 같은 사진을 인식하도록 학습한 것이 X-ray Scan을 읽어서 방사선 진단에 도움이 될 수 있다. Transfer Learning은 다음과 같이 적용한다.
우선, 학습한 신경망 네트워크의 마지막 output layer를 삭제하고, 마지막 layer의 파라미터, weight(and bias)도 삭제한다. 그리고, 마지막 layer를 새로 만들고, 무작위로 초기화된 weight를 만든다. 이렇게 생성한 layer들을 통해서 진단의 결과값을 나타내는 것이다.
구체적으로 설명하자면, 이미지 인식 업무에 관련해서 파라미터를 학습을 시킨 것을 사용하는 것이고, 이 학습 알고리즘을 방사선 이미지에 transfer를 진행한다. data set (x, y)를 방사선 이미지로 바꾸어 주고, 마지막 output layer의 파라미터 W^{[L]}, b^{[L]}을 초기화시킨다. 그리고 새로운 dataset에서 NN을 다시 학습시키면 된다.
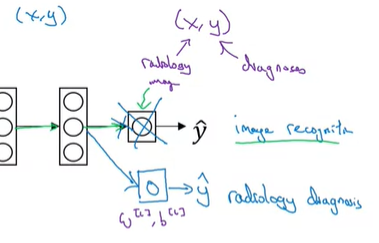
기존 학습 알고리즘을 가지고 다시 학습하는 경우에 방법이 새로운 dataset에 따라서 두 가지의 방법이 있다.
만약, 방사선 이미지 dataset이 많지 않다면, 마지막 층의 파라미터만 초기화하고 나머지 layer의 파라미터는 고정시켜서 학습시킬 수 있다. 만약, 데이터가 충분히 많다면, 나머지 layer에 대해서도 다시 학습시킬 수 있다.
(경험상, dataset의 크기가 작다면 output layer만 다시 학습하거나, 마지막 2개 layer정도만 다시 학습시키는 것이 좋다.)
모든 layer의 파라미터를 다시 트레이닝시키는 경우에, 이미지 인식 기능에 대해서 첫번째 학습을 Pre-training이라고 부른다.(신경망의 파라미터를 pre-initialize or pre-training하기 위해서 이미지 인식 데이터를 사용하기 때문)
그리고, 방사선 이미지에 학습시키는 두번째 단계를 종종 fine tuning이라고 한다.
이렇게 이미지 인식 기능에서 학습한 내용을 방사선 이미지를 인식하고 진단하는 것으로 이양(transfer)시킨 것이다. 이것이 가능한 이유는 edges를 감지하거나, curve를 감지, 또는 positive objects를 감지하는 low level features(특성) 때문이다. 이미지 인식을 위한 데이터셋(고양이, 개 등)에서 이미지의 구조, 이미지가 어떻게 생겼는지에 대해서, 즉, 이미지들의 부분부분들을 인식하도록 학습한 것들이 (가지고 있는 방사선 이미지 dataset이 적더라도)방사선 이미지 인식에도 유용할 수 있다.
정리하자면, Transfer Learning은 Task A와 Task B가 같은 입력(이미지나 음성같은)으로 구성되어 있고, Task A의 데이터가 Task B의 데이터보다 훨씬 더 많은 경우에 가능하다. 조금 더 추가하자면, Task A에서 학습하는 low level 특성이 Task B를 학습하는데 도움이 될 수 있다고 판단되는 경우에 사용할 수 있다.
Multi-task Learning
Transfer Learning이 순차적으로 Task A를 학습하고 Task B로 넘어가는 절차가 있었다면, Multi-task Learning은 동시에 학습을 진행한다. NN이 여러가지 Task를 할 수 있도록 만들고, 각각의 Task가 다른 Task들을 도와주는 역할을 한다.
우리가 자율주행 자동차를 만든다고 생각해보자. 이런 자율주행 자동차는 보행자나 다른 차량, 정지 표지판, 신호등 등을 잘 감지해야 한다.

위 왼쪽 이미지를 보면, 정지 표지판과 차량이 있고, 보행자나 신호등은 보이지 않는다. 이 이미지가 input x^{(i)}라고 한다면, output y^{(i)}는 하나의 label이 아닌 4개의 label이 필요할 것이다. 만약 더 많은 것들을 감지하려고 한다면, 4개가 아니라 더 많은 label을 가질 수 있을 것이다.(여기서는 4개만 감지한다고 가정한다)
그러면 y^{(i)}는 4x1 vector가 되고, dataset 전체를 참조하면, Y matrix는 오른쪽 아래처럼 4 x m matrix가 된다.
우리는 y값을 예측하기 위해서 NN을 학습시키는 것이고, input x를 가지고, output \hat{y}를 구하는게 목적이다.
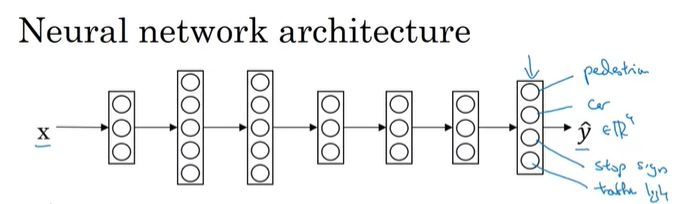
위의 Neural Network를 학습하기 위해서는 NN의 Loss를 정의해야 한다.
예측값은 4x1 vector인 \hat{y}이기 때문에, Loss는 다음과 같이 구할 수 있다.
\text{Loss } = \frac{1}{m}\sum_{i = 1}^{m}\sum_{j = 1}^{j = 4}\mathscr{L}(\hat{y}_j^{(i)}, y_j^{(i)})
그리고 Loss는 보통 Logistic Loss를 사용하고, \mathscr{L}(\hat{y}_j^{(i)}, y_j^{(i)}) = -y_j^{(i)}log(\hat{y}_j^{(i)}) - (1 - y_j^{(i)})log(1 - \hat{y}_j^{(i)}) 이다.
여기서 이미지는 복수의 label을 가질 수 있다. 따라서, 우리는 이미지가 보행자나 자동차, 정지 표지판, 신호등으로 판단하는 것이 아니라, 하나의 이미지에 대해서 보행자, 차량, 정지 표지판, 신호등이 있는지 판단하는 것이기 때문에, 여러 개의 물체가 같은 이미지에 존재할 수 있다는 것이다. 여기서 결과는 4개의 label을 가지고, 이미지가 4개의 물체를 포함하고 있는지 알려주는 역할을 한다.
우리가 사용할 수 있는 또 다른 방법은 4개의 NN을 각각 트레이닝시키는 것이다. 하지만 NN의 초반 특성들 중의 일부가 다른 물체들과 공유될 수 있다면, 이렇게 4개의 NN을 각각 트레이닝시키는 것보다, 한 개의 NN을 학습시켜서 4개의 일을 할 수 있도록 하는 것이 보통 더 좋은 성능을 갖는다.
부가적인 내용으로, 이제까지 학습을 하기 위한 데이터의 label이 모두 달려있는 것처럼 설명했지만, multi-task learning은 어떤 이미지가 일부 물체에 대해서만 label이 되어 있더라도 잘 동작한다.

위 레이블처럼 레이블하는 사람이 귀찮거나, 실수로 레이블하지 않았아서 물음표로 나타나더라도 알고리즘을 학습시킬 수 있다. 이런 경우에 Loss를 구할 때에는 물음표는 제외하고 y의 값이 0이거나 1인 것들만 취급해서 Loss를 구한다.
Multi-Tasking은 언제 사용할 수 있을까?
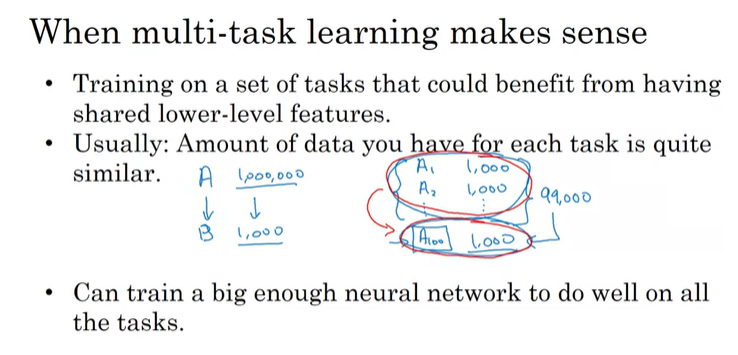
첫 번째로 각각의 task들을 학습할 때, lower-level 특성을 서로 공유해서 유용하게 사용될 수 있는 경우에 가능하다.
두 번째는 필수 규칙은 아니고, 항상 옳지도 않지만, 각각의 task의 dataset의 양이 유사할 때 가능하다. 엄격하게 적용되는 것은 아니지만, multi-task learning이 효과가 있으려면, 보통 다른 task들의 data의 합이 하나의 task의 양보다 훨씬 많아야 한다.
마지막은, 충분히 큰 neural network에서 학습시키는 경우에 잘 동작한다. Rich Carona 연구원은 multi-task learning이 각각의 NN으로 학습하는 것보다 성능이 좋지 않다면, NN이 충분히 크기 못하는 경우라는 것을 발견했다.
실제로, multi-task learning은 transfer learning보다 훨씬 더 적게 사용되며, transfer learning의 경우에는 data는 적지만, 문제 해결을 위해 사용되는 경우를 자주 보게 된다.
예외적으로 computer vision object detection영역에서는 transfer learning보다 multi-task learning이 더 자주 사용되며, 개별적인 NN으로 학습하는 것보다 더 잘 동작한다.
What is End-to-end Deep Learning?
최근 개발된 것 중에 흥미로운 것 중 하나는 End-to-end deep learning의 발전이다. End-to-end deep learning은 여러 단계의 process를 거치는 것들을 하나의 NN으로 변환하는 것이다.
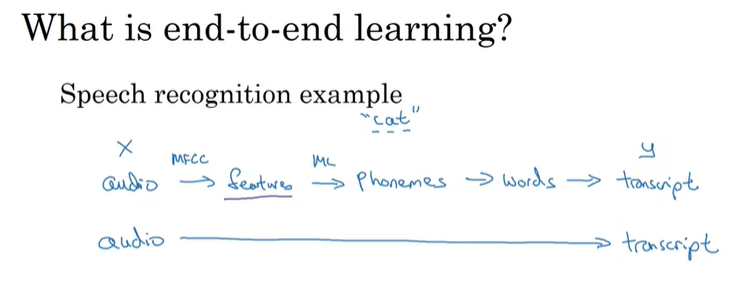
음성 인식을 예로 들어보면, input x인 오디오를 사용해서 output y에 매핑하면 오디오 클립이 글로 옮겨지게 되는 것이다. 이전에 음성 인식은 많은 단계가 필요했다. 먼저, 오디오의 hand-designed feature(사람이 직접 feature들을 지정)들을 추출한다. MFCC라는 알고리즘을 사용할 수 있는데, 이 알고리즘은 오디오의 hand-designed feature와 low-level feature를 추출하는 알고리즘이다. 그리고 머신러닝을 적용해서 Phonemes(음소; 소리의 기본단위)를 추출한다. 그런 다음에 음소들을 묶어서 words 형태로 만들고, 글로 나타낸다.
반대로 End-to-end deep learning은 하나의 거대한 Neural Network를 학습시켜서, 오디오 클립을 입력하고 다이렉트로 문자로 출력하도록 하는 것이다.
End-to-end learning이 효과를 나타내기 시작하면서, 많은 연구원들이 개별적인 단계를 설정하기 위해서 파이프라인을 설계하는 시간을 줄이게 되었다.
Whether to use End-to-end Deep Learning
장점
- 완벽한 학습을 통해서 데이터가 말을 하는 것처럼 할 수 있다. 우리가 충분히 많은 데이터를 가지고 있다면, X -> Y에 매핑되는 기능을 만들어낼 수 있다. 예를 들어, 이전의 음성 인식 시스템에서는 단어의 기본 음절 단위를 가지고(음성학) 해석을 하는데, 학습 알고리즘이 음성학적으로 생각하지 않고, 음성 표현이 바로 해석된다면, 전체적인 성과는 더 좋아질 것이다.
- 수작업이 줄어듬. 이 경우에는 워크플로우가 단순해지고, 중간 과정들을 설계하는데 많은 시간을 투자하지 않아도 된다.
단점
- 데이터가 많이 필요하다. X-Y 매핑을 바로 하기 위한 데이터가 필요하다. 이전 강의에서는 하위 작업인 얼굴 인식과 얼굴을 식별하기 위한 데이터들은 많았지만, 이미지를 바로 식별하기 위한 데이터는 거의 없었다. 그래서 이런 시스템을 훈련시키기 위해서는 입력과 출력이 모두 필요한 데이터가 필요하다.
- 유용하게 수작업으로 설계된 component들을 배제한다는 것이다. 데이터가 많지 않다면, train set으로 얻을 수 있는 것이 적고, 잘 설계된 hand-designed component를 사용하는 것이 더 좋은 성능을 낼 수 있다.
End-to-end deel learning을 적용하기 위해서 중요한 질문은, x -> y로 매핑시키기 위해 필요한 데이터가 충분히 많은가의 여부이다. 이전 강의에서 봤듯이, 뼈를 인식하는 것과 인식 뼈를 토대로 나이를 추정하는 것은 데이터가 많이 필요하지 않을 수 있지만, 뼈 사진을 통해서 바로 나이를 매핑하는 것은 복잡한 문제처럼 보이고, 많은 데이터가 필요할 것이다.
'Google ML Bootcamp' 카테고리의 다른 글
| [CNN]Deep Convolutional Models : Case Studies (0) | 2022.07.25 |
|---|---|
| [CNN] Foundations of Convolutional Neural Networks (0) | 2022.07.21 |
| Optimization Algorithms (0) | 2022.07.13 |
| practical aspects of deep learning (0) | 2022.07.11 |
| Logistic Regression as a Neural Network (0) | 2022.06.23 |