우리가 사용하는 데이터 중에는 Sequence data(음성인식이라던지 자연어라던지 등의 문맥이 있는 데이터)들이 상당히 많이 있다. 이는 하나의 단어만 알고 이해한다고 전체 맥락을 이해할수 없듯, 이전의 단어들을 이해해야 전체의 맥락을 이해 할 수 있다.이런 맥락들이 있는 series 데이터는 NN/CNN에서 사용하기 어렵다. RNN은 시퀀스 데이터를 처리하기에 적합한 모델이며 어떤 것을 시퀀스로 정의하냐에 따라서 NLP, time series, image 등 다양한 문제들을 해결할 수 있다.
2. RNN 구조
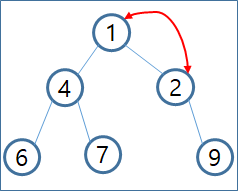
RNN은 순환 신경망으로써 아래 그림처럼 인접한 다음 노드로만 계산되는 것이 아니라 자기자신에게 혹은 그 전 노드로 계산되는 구조를 볼 수 있습니다.
위의 그림처럼 현재 시점 t까지의 데이터가 있으며 현재 상황에서 x1~xt까지 순차적인 상황일 것입니다. 왼쪽 그림의 계속해서 정보를 넘겨준다는 표현을 풀어서 오른쪽 그림처럼 이해가기 쉽게 표현한 상황입니다.
결국RNN은 전 시점의 어떤 정보를 다음 시점으로 넘겨준다고 볼 수 있습니다. 다음 시점의 정보는 전 시점의 정보만이 아니라 이전까지의 정보들을 모두 가지고 있을 것입니다. 그리고 이처럼 정보를 가지고 있는 것을 cell이라고 하며 현재 cell이 가지고 있는 정보, 즉 다음 시점으로 넘겨줄 정보를 hidden state라고 명명합니다. RNN의 수식은 아래와 같이 표현할 수 있습니다.
이것은 입력으로 들어온 문장을 끊어서 품사 구별을 하는 과정이다.
조금 더 자세히 확인하면 아래와 같은데,
가장 위 박스 속 target이 예측 대상이고 pred가 예측 값이다. 결국에 이 둘 사이의 오차를 최소화하는 방향으로 학습하는 것이 RNN 모델이다.
연산되는 과정이 보이는 가운데의 박스는 hidden state이다. 이때 이전에서 넘어온 weight, input에서의 weight 두 가중치를 모두 고려해준다. 여기서 '고려한다'라는 말은 수식으로+를 사용해 표현한다. 그리고 딥러닝 모델의 학습을 더 수월하게 해주는 편향값을b로 표시하고 있다. 그 후,tanh활성화 함수 적용을 해 비선형성을 주어 그 출력으로 output을 도출한다.
마지막으로softmax를 거쳐 품사의 확률값을 확인할 수 있게 된다.
RNN의 특징
RNN은 순환 경로를 갖기 때문에 이전 데이터를 기억하는 특징이 있다. 그리고 그 동시에 최신 데이터로 갱신을 할 수 있다.
위의 다이어그램은 RNN 순환 구조를 펼쳐 보기 쉽게 확인한 것이다. 이것을 단순화하여 나타내면 순환 구조라는게 조금 더 이해가 된다.
오른쪽이 위 다이어그램이고 왼쪽이 단순화한 구조이다. 화살표 방향으로 쉽게 이해할 수 있다.
그리고 최종 수식이 아래와 같이 정의된다.
그리고 감정 분석 등을 할 때 오차 역전파를 통해 예측값과 실제값 사이의 오차를 줄여나가도록 한다.
back propagation through time을 통해 빨간 글씨로 표시된 가중치 2개의 값과 편향값을 변경하면서 최소화해나가는 방식으로 학습이 진행된다. 그런데 이때 RNN에서 오차 역전파법을 적용하는데 그 깊이가 너무 깊어지다 보면, 계속해서 미분하기 때문에 기울기가 0에 가까워지는 Vanishing Gradient Problem(기울기 소실 문제) 을 주의해야한다.
3. LSTM
LSTM은 RNN이 오래된 것을 기억하지 못하는, 기울기 소실 문제를 해결하기 위해 탄생했다. LSTM 알고리즘은 기억할 것과 잊을 것을 선택해 중요한 정보만 기억하는 것이 핵심이다. LSTM도 RNN과 동일하게 입력과 가중치를 곱하고 절편을 더해 활성화 함수를 통과시키는 층을 여러 개 가지고 있다.
RNN과의 차이점은 순환되는 층이 2개라는 것이다. Hidden state와 Cell state에서 과거 정보가 순환한다. Cell state는 Hidden state와 달리 다음 층으로 전달되지 않는다. 또한 LSTM은 Gate를 통해서 정보를 통제한다. 이름대로 지나갈 수 있는 문을 만들어서 원하는 정보만 통과시키는 방법이다.
Input Gate 현재 정보를 얼마나 기억할 지 결정하는 Gate이다. 이전 층의 hidden state에는 tanh를 곱하고 새로운 정보에는 sigmoid 활성함수를 곱한다. 새로운 특성에 sigmoid를 곱하기 때문에 0~1 사이의 결과값으로 새로운 정보를 얼마나 사용할 지 결정한다.
Forget Gate 정보를 얼마나 잊어버릴지 결정하는 Gate이다. 입력과 hidden state를 서로 다른 가중치를 곱한 다음 sigmoid 활성 함수를 통과시킨다. 0~1 사이의 결과값을 얻기 때문에 얼마나 정보를 잊을 지 결정할 수 있다. 이전 타임스텝의 Cell state와 곱하여 새로운 Cell state를 만든다.
Output gate 다음 층으로 전달할 hidden state를 만드는 Gate이다. 먼저, 이전 hidden state값과 입력 값에 각각 다른 가중치를 곱하고 sigmoid 활성 함수를 통과시킨다. 그 출력 값과 현재 Cell state 값을 tanh 활성 함수에 통과시킨 값을 서로 곱해서 hidden state를 만든다.
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.LSTM(n))
코드도 RNN과 비슷하다. RNN 부분을 LSTM으로 바꿔주기만 하면 된다. n에는 Cell에서 사용하고 싶은 뉴런 개수를 입력하면 된다.
4. GRU
LSTM을 개선한 모델이다. LSTM보다 파라미터가 더욱 적어 연산 비용도 적고, 모델도 간단해 학습 속도가 더 빠르지만 비슷한 성능을 내는 모델이다. Forget Gate와 Input Gate를 합쳐 Update Gate를 만들고, Reset Gate를 추가했다.
Update Gate Forget Gate와 Input Gate를 합친 Gate이다. 이전의 정보를 얼마나 통과시킬지 결정하는 Gate이다. 입력 값과 hidden state 값을 각각 가중치에 곱하고 sigmoid 함수에 통과시켜 Forget Gate로 사용한다. 이 값을 1에서 빼 Input Gate로 사용한다.
Reset Gate 이전 hidden state의 정보를 얼마나 잊을 지를 결정하는 Gate이다. Sigmoid 활성함수를 통과시켜 0~1 사이의 범위로 잊을 정보의 양을 결정한다.
from tensorflow import keras
model = keras.Sequentail()
model.add(keras.layers.GRU())
DFS(Depth1-First Search)와 BFS(Breadth2-First Search)는 그래프 탐색 알고리즘(Graph traversal algorithm)이다. 그래프 탐색 알고리즘이란, 그래프의 모든 꼭짓점(Node 또는 Vertex라 한다)을 방문하는 알고리즘을 의미한다.
DFS는 구현이 간단하다. 시간 복잡도는O(N)이며, 재귀 함수로 구현하면 굳이 스택을 사용하지 않아도 되다.
graph = [
[], # 0
[2, 3], # 1
[4, 5], # 2
[6], # 3
[2, 5], # 4
[2, 4], # 5
[3, 7], # 6
[6] # 7
]
# 방문 정보를 기록하기 위한 리스트
visited = [False] * 8defdfs(v):# 방문 표시
visited[v] = Trueprint(v, end=' ')
# 그래프를 순환하면서 인접 노드들을 방문for i in graph[v]:
# 만약 방문하지 않은 노드가 있다면ifnot visited[i]:
# 탐색 시작
dfs(i)
# 탐색 시작 노드 1을 넣어주며 dfs() 실행
dfs(1)
BFS
BFS 너비 우선 탐색이라는 이름에 걸맞게 그래프의 너비부터 탐색한다. DFS가 세로로 탐색하는 반면, BFS는 그래프를 가로로 탐색한다. DFS는 인접 노드의 인접 노드를 계속해서 탐색해 가지만, BFS는 인접 노드를 계속 큐에 넣어가며 큐에 들어온 순서대로 탐색을 시작하기에 시작 노드에서부터 가까운 노드들부터 탐색한다는 의미이다.
구체적인 동작 과정:
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리.
2. 큐에서 노드를 꺼내 해당 노드의 방문하지 않은 모든 인접 노드를 모두 쿠에 삽입하고 방문 처리.
Stack은 LIFO (Last In First Out)로 나중에 쌓은 순서대로 꺼냅니다. 반면에 Queue는 파이프와 같이 FIFO (First In First Out)로 먼저 들어간게 먼저 나옵니다.
근데 문제는 이런 형태만 있는것이 아니라 , 쌓을때부터 순서를 고려해야 하는 경우도 있습니다. Stack 과 Queue가 쌓거나 넣은 순서대로 꺼낸다면 Priority Queue는 우선순위가 존재해서 우선 순위가 높은 데이터부터 꺼내도록 구현된 자료구조입니다.
Heap은 Priority Queue와 같이 우선 순위가 존재하는 자료구조 입니다.
1. Heap을 사용하는 이유
앞서 말한것 처럼 Priority Queue를 구현하기 위해 Heap이라는 자료구조를 사용합니다.
배열에서 데이터의 최대, 최소값을 찾기위해서는 O(n)이 걸리는데 비해 Heap은 O(log n)으로 성능이 더 좋습니다.
2. Heap이란?
데이터에서 최대값과 최소값을 빠르게 찾기 위해 만들어진 완전이진트리입니다. Root에 최대값이 있는 Max Heap과 Root에 최소값이 있는 Min Heap으로 구분됩니다.
Max Heap의 경우 Heap의 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 커야 합니다. Heap은 좌측부터 채워나가지만 형제 노드들간에는 좌/우를 불문하고 크기를 구분하지 않습니다. Min Heap의 경우 반대로 각 노드의 값은 해당 노드들의 자식 노드가 가진 값보다 작아야 합니다.
- 이진트리 (binary tree) : 모든 노드들의 자식 노드가 두개 이하인 트리
- 완전이진트리(complete binary tree) : 부모, 왼쪽자식, 오른쪽 자식 순으로 채워지는 트리
3. Heap 과 Binary Search Tree의 차이
둘다 이진 트리입니다. Binary Search Tree는 왼쪽 자식 노드, 부모노드, 오른쪽 자식노드의 순으로 크기가 크지만 Heap은 순서가 없습니다.
Binary Search Tree는 탐색용 자료구조, Heap은 최대, 최소 검색을 위한 자료구조로 사용됩니다.
4. Heap의 원리
Min Heap을 기준으로 설명합니다. 구글에서 검색해서 붙이려다 직접 그림도 다 그렸습니다 (미쳤다)
Max Heap은 반대입니다.
값을 하나씩 트리의 노드에 좌에서 우로 할당.
부모노드의 값이 자식노드보다 크면 부모와 자식을 교체
루트노드까지 비교를 반복
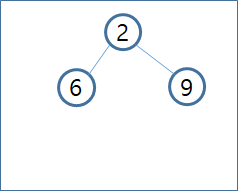
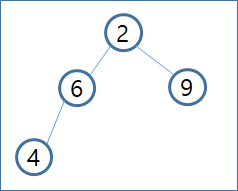
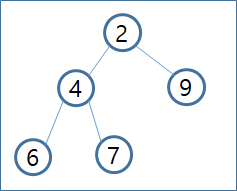
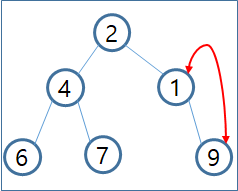
- Heap Tree에 2 , 6, 9, 4, 7, 1 의 순서로 데이터가 추가된다고 할때 아래와 같이 처리됩니다.
5. 파이썬에서 Heap 구현하기
(생략 ^^;;)
6. 파이썬에서 Heap 기능 사용하기
파이썬은 내장기능으로 heapq 를 제공하고 있습니다.
아래처럼 heapq를 사용하여 Heap을 사용할 수 있습니다. 문제는 heapq는 Min Heap의 기능만 제공합니다. (왜!!!)
일반 DNN은 기본적으로 1차원 형태의 데이터를 사용한다. 따라서 이미지가 입력될 경우, 이것을 flatten 시켜서 한줄의 데이터로 만들게 된다. 이 과정에서 이미지의 공간적 정보가 손실되어, 특징 추출과 학습이 비효율적이고 정확도의 한계가 발생한다는 문제가 있었다. 그래서 CNN(Convolutional Neural Network)을 통해 이미지를 raw input으로 받음으로써, 공간적/지역적 정보를 그대로 유지한채 특성들의 계층을 빌드업하게 된다.
<식 3>로 계산된 출력 데이터(Activation Map)의 Shape은 (36, 28, 20) 입니다. Convolution Layer 1에서 학습시킬 대상은 입력 채널 1, 필터 사이즈 (4, 4), 출력 채널 20개 입니다. 따라서 이 레이어의 학습 파라미터는 320개 (4X4X20) 입니다.
입력 채널: 1
출력 데이터(Activation Map) Shape: (36, 28, 20)
학습 파라미터: 320개 (1 X 4 X 4 X 20)
3.1.2 Max Pooling Layer 1
Max Pooling Layer 1의 입력 데이터의 Shape은 (36, 28, 20)입니다. Max Pooling 크기가 (2, 2)이기 때문에 출력 데이터 크기는 <식 4>와 같이 계산될 수 있습니다.
<식 4>으로 계산된 출력 데이터의 Shape은 (18, 14, 20) 입니다. Max Pooling Layer에서 학습 파라미터가 없습니다.
입력 채널: 20
출력 데이터 Shape: (18, 14, 20)
학습 파라미터: 0
3.2 Layer 2의 Shape과 파라미터
Layer 2는 1개의 Convolution Layer와 1개의 Pooling Layer로 구성됩니다. 두 레이어이 출력 데이터 shape과 파라미터는 다음과 같이 계산할 수 있습니다.
3.2.1 Convolution Layer 2
Convolution Layer 2의 기본 정보는 다음과 같습니다.
입력 데이터 Shape = (18, 14, 20)
입력 채널 = 20
필터 = (3, 3, 40)
출력 채널 = 40
Stride = 1
입력 이미지에 Shape이 (3, 3)인 필터 40개를 적용할 경우 출력 데이터(Activation Map)의 Shape을 계산하는 과정은 <식 5>과 같습니다.
식 5. Convolution Layer 2의 Activation Map 크기 계산 RowSize = (18-3)+1/1 = 16 ColumnSize = (14-3)+1/1 = 12
<식 5>로 계산된 출력 데이터(Activation Map)의 Shape은 (16, 12, 40)입니다. Convolution Layer 1에서 학습시킬 대상은 입력 채널 20, 필터 사이즈 (3, 3), 출력 필터 40개입니다. 따라서 이 레이어의 학습 파라미터는 7200개 (20 X 3 X 3 X 40) 입니다.
입력 채널: 20
출력 데이터(Activation Map) Shape: (16, 12, 40)
학습 파라미터: 7,200개 (20X3X3X40)
3.2.2 Max Pooling Layer 2
Max Pooling Layer 2의 입력 데이터의 Shape은 (16, 12, 40)입니다. Max Pooling 크기가 (2, 2)이기 때문에 출력 데이터 크기는 <식 6>와 같이 계산될 수 있습니다.
식 6. Max Pooling Layer 2의 출력 데이터 크기 계산 16/2 = 8 12/2 = 6
<식 6>로 계산된 출력 데이터(Activation Map)의 Shape은 (8, 6, 40) 입니다. Max Pooling Layer에서 학습 파라미터가 없습니다.
입력 채널: 40
출력 데이터 Shape: (8, 6, 40)
학습 파라미터: 0
3.3 Layer 3의 Shape과 파라미터
Layer 3도 1개의 Convolution Layer와 1개의 Pooling Layer로 구성됩니다. 두 레이어이 출력 데이터 shape과 파라미터는 다음과 같이 계산할 수 있습니다.
3.3.1 Convolution Layer 3
Convolution Layer 3의 기본 정보는 다음과 같습니다.
입력 데이터 Shape = (8, 6, 40)
입력 채널 = 40
필터=(3, 3)
출력 채널 = 60
Stride = 1
입력 이미지에 Shape이 (3, 3)인 필터 60개를 적용할 경우 출력 데이터(Activation Map)의 Shape을 계산하는 과정은 <식 7>과 같습니다.
식 7. Convolution Layer 3의 Activation Map 크기 계산 RowSize = (8-3)+1/1 = 6 ColumnSize = (6-3)+1/1 = 4
<식 7>로 계산된 출력 데이터(Activation Map)의 Shape은 (6, 4, 60)입니다. Convolution Layer 1에서 학습시킬 대상은 (3, 3) 필터 60개입니다. 따라서 이 레이어의 학습 파라미터는 21,600개 (40X3X3X60) 입니다.
입력 채널: 40
출력 데이터(Activation Map) Shape: (6, 4, 60)
학습 파라미터: 21,600개 (40X3X3X60)
3.3.2 Max Pooling Layer 3
Max Pooling Layer 3의 입력 데이터의 Shape은 (6, 4, 60)입니다. Max Pooling 크기가 (2, 2)이기 때문에 출력 데이터 크기는 <식 8>과 같이 계산될 수 있습니다.
식 8. Max Pooling Layer 3의 출력 데이터 크기 계산 6/2 = 3 4/2 = 2
<식 8>로 계산된 출력 데이터(Activation Map)의 Shape은 (3, 2, 60)입니다. Max Pooling Layer에서 학습 파라미터가 없습니다.
입력 채널: 60
출력 데이터 Shape: (3, 2, 60)
학습 파라미터: 0
3.4 Layer 4의 Shape과 파라미터
Layer 3도 1개의 Convolution Layer로 구성됩니다. 이 레이어의 출력 데이터 shape과 파라미터는 다음과 같이 계산할 수 있습니다.
3.4.1 Convolution Layer 4
Convolution Layer 4의 기본 정보는 다음과 같습니다.
입력 데이터 Shape = (3, 2, 60)
입력 채널 = 60
필터=(2, 2)
출력 채널 = 80
Stride = 1
입력 이미지에 Shape이 (2, 2)인 필터 80개를 적용할 경우 출력 데이터(Activation Map)의 Shape을 계산하는 과정은 <식 9>과 같습니다.
식 9. Convolution Layer 4의 Activation Map 크기 계산 RowSize = (3-2)+1/1 = 2 ColumnSize = (2-2)+1/1 = 1
<식 9>로 계산된 출력 데이터(Activation Map)의 Shape은 (2, 1, 80)입니다. Convolution Layer 1에서 학습시킬 대상은 입력 채널 60, 필터 사이즈 (2, 2), 출력 채널 80개입니다. 따라서 이 레이어의 학습 파라미터는 19,200개 (60X2X2X80)입니다.
입력 채널: 60
출력 데이터(Activation Map) Shape: (2, 1, 80)
학습 파라미터: 19,200개 (2X2X80)
3.5 Flatten Layer의 Shape
Flatten Layer는 CNN의 데이터 타입을 Fully Connected Neural Network의 형태로 변경하는 레이어입니다. Flatten 레이어에는 파라미터가 존재하지 않고, 입력 데이터의 Shape 변경만 수행합니다.
입력 데이터 Shape =(2, 1, 80)
출력 데이터 Shape =(160, 1)
3.6 Softmax Layer
이 레이어의 입력 데이터 Shape은 (160, 1)입니다. 이 네트워크의 분류 클래스가 100개이기 때문에 최종 데이터의 Shape은 (100, 1)입니다.
입력 데이터의 shape: (160, 1)
출력 데이터의 shape: (100, 1)
이때 Weight Shape은 (100, 160)입니다. Softmax 레이어이 파라미터는 160,000개 (100X160)입니다.
3.7 전체 파라미터 수와 레이어별 Input/Output 요약
layerinput channelFilteroutput channelStridePooling활성함수Input ShapeOutput Shape파라미터 수
손실함수는'예측값과 실제값의 차이를 수치화'하는 함수이다. 손실함수는 패널티로 작용되며, 손실함수가 작을수록 인공지능의 성능은 좋아진다. 따라서 모델이학습을 하는 과정은손실함수 값을 최소화하기 위한 과정이라고도 할 수 있다. 손실함수로는 평균 제곱오차 MSE 와 교차엔트로피가 있다. (이 책에서는 교차엔트로피만 사용함) 이런 손실함수도 결국에는 '함수' 이므로 당연히 변수를 갖는다. 그렇다면 이 손실'함수'의 변수는 무엇일까?
손실함수의 변수
가중치와 편향이 손실함수의 변수이고, 입력 데이터는 손실함수의 계수이다. cf. 함수에서 변수는 변할 수 있는 수이고, 계수는 변하지 않는 수이다. ex. f(x) = ax + b 이면 a와 b는 계수, x는 변수 '입력되는 값'이라는 이미지 때문에 손실함수의 변수를 데이터로 착각하기 쉽지만, 입력된데이터는 우리가 변화시킬 수 없으므로, 가중치와 편향을 조절하여 손실함수의 값을 줄여야 한다. 따라서 머신러닝의 과정은가중치와 편향을 조절하여 손실함수(loss)를 줄여나가는 과정이라 할 수 있다.
ex. 라벨이 (0,0,1)일때 왼쪽 신경망에 Affine, Softmax, Loss function을 적용해보자.
Loss function(cross entropy) : -Σ(0,0,1)log(softmax 값) = - log(exp(a3)/exp(a1)+exp(a2)+exp(a3))
최종 손실함수 값
위 손실함수 값이 작을수록 잘 훈련된 모델이다. 이때 데이터의 값 x는 바꿀 수 없으므로 이 신경망의 손실함수에서 가중치와 편향인 w11, w12, w13, w21, w22, w23와 b1, b2, b3가 변수임을 다시 한번 확인할 수 있다.
손실함수의 변수 개수
각 층에 784, 50, 10개의 유닛이 있는 신경망의 경우 w 는 이전 유닛과 이후 유닛을 모두 연결해야 하고(=이전 유닛*이후 유닛), b는 이후 유닛만큼 있으면 되므로 손실함수 변수의 개수는 총 784×50+50+50×10+10=39,760 개이다. 추후 모델을 학습시킬 때 model.summary() 의 출력 중[ Total params : ]부분에서 손실함수에서 사용된 변수(가중치 + 편향)의 개수를 알 수 있다.
cf. 입력 유닛이 784개인 이유 : 28*28 크기의 행렬 이미지를 784차원 벡터로 flatten 하므로
경사하강법(GD - gradient descent)
등장 배경
앞에서 말했다싶이, 머신러닝은손실함수의 값을 최소화시키는 가중치와 편향을 구하는 과정이다. 수학에서 최소를 구할 때, 가장 일반적인 방법은 n변수 함수를 각각의 변수로 미분하여 n개의 방정식을 푸는 방법이다. 하지만 이 모델에서 우리가 구해야 하는 변수의 개수는 39,760개이므로 최소 39,760개의 미분 방정식을 풀어야 한다. 또한 이런 계산을 n번 반복해야 모델이 '학습'을 할 수 있으므로 모델을 학습시키기 위해서는 굉장히 많은 계산을 해야한다. 이는 매우 비효율적이므로, 머신러닝에서는 손실함수의함수값이 최소값이 되게하는 변수를 구하기 위해 또 다른 방법을 사용한다.
경사하강법이란?
경사하강법을 비유하자면,최단시간에 눈을 감고 산을 내려가는 것과 비슷하다. 눈을 감고 최단시간에 산을 내려가기 위해서는 현 위치에서 내려가는 경사가 가장 심한 쪽을 찾고, 한 바자국 이동하고, 다시 그 위치에서 경사가 가장 심한 쪽을 찾고, 이동하고,.. 하는 과정을 반복하면 된다. 이를 수학적으로 나타내보자. 앞서 우리는방향미분 값이 최소가 되는 방향즉,함수값이 가장 빨리 감소하는 방향은gradient의 반대 방향이라는 것을 배웠다. 따라서 변수를gradient 반대방향으로 이동시키며 이를 계속 갱신시키면 된다.
경사하강법의 문제점 1 - 이동폭
이동 폭이 너무 크면 무질서하게 움직이고, 이동 폭이 너무 작으면 목적지까지 여러번 움직여야 한다는 문제점이 발생한다.
경사하강법의 문제점 2 - 극소점, 안장점
앞서 말했듯이 경사하강법은 산을 '눈감고' 내려가는 것과 비슷하다. 39,760개의 변수를 갖는 함수는 39,760 차원에 그려질텐데, 우리는 이 모양을 상상할 수 없기 때문이다. 따라서 변수의 보정폭이 적은 ( = gradient가 0에 가까운 ) 부분이 최소점인지, 극소점인지, 안장점인지 알 수 없다. 그저 gradient가 작은 쪽으로 향하다보면 최소점이 아닌 다른 점에 안착할 수 있다는 문제점이 있다.
경사하강법의 문제점 3 - 시간
손실함수의 값을 구하기 위해선, 하나의 데이터를 손실함수에 대입해야 한다. 하지만 모델을 학습시킬 때는 하나의 데이터가 아닌 '데이터셋'을 입력해야 한다. 경사하강법을 그대로 적용한다면 데이터셋의 크기만큼 변수 업데이트를 실행해야 하는데, 이는 굉장히 비효율적이다. 예를들어, MNIST의 경우 데이터셋에 6만개의 테스트 데이터가 담겨있다. 한번 변수를 업데이트 할 때마다 6만개의 데이터를 다 대입해야 하는데, 미분을 통해 업데이트까지 반복해야하므로, 실행에 굉장히 오래 걸린다. 이 문제를 해결하기 위해 Stochastic Gradient Descent(SGD) 방법을 사용한다.
경사하강법의 문제점 4 - 등위면과 gradient는 수직
앞서 배운 것 처럼 gradient와 등위면(선)은 항상 수직이다. 따라서 gradient의 반대 방향으로 움직인다는 것은 곧 등위면(선)과 수직으로 움직인다는 것을 의미한다. 등위면에 수직으로 움직이게 되면 목적 지점까지 지그재그로 진동하며 움직이게 되는데 이러한 과정은 매우 비효율적이다.
Stochastic Gradient Descent
한번의 최적화에 전체 데이터셋을 넣는 경사하강법과 달리 SGD는적은 양의 데이터를 나누어 입력한다. (mini batch) 전체 데이터를 입력하는게 아니므로정확도는 떨어지지만, 한번 시행에 걸리는 시간은 줄어든다. 결과적으로, 빨라진 시간을 이용해 여러번 최적화 할 수 있으므로 더 효율적으로 오차를 줄일 수 있다.
Optimizer
머신러닝에서 오차가 줄어들도록 변수를 최적화하는 방법을 옵티마이저라고 한다. '시간이 오래 걸린다'는 경사하강법의 문제를 해결하기 위해 SGD가 나온 것 처럼, 경사하강법의 원리를 바탕으로하여 훨씬 개선된 옵티마이저들이 개발되어왔다. 아래 옵티마이저들의 모든 원리를 다룰순 없지만, 모두 손실함수의 변수인 가중치와 편차를 최적화하기 위해 사용된다는 점은 기억해두자!!
v : 일종의 속도와 같은 개념으로 생각하는 것이 이해에 도움, v의 영향으로 인해 가중치가 감소하던(or 증가하던) 방향으로 더 많이 변화하게 되는 것. 최초의 v는 0으로 초기화
2-3. Nesterov accelerated gradient
2-4. Adagrad
신경망 학습에서는 학습률(수식에서는η) 값이 중요하다. 이 값이 너무 작으면 학습 시간이 너무 길어지고, 반대로 너무 크면 발산하여 학습이 제대로 이뤄지지 않음
이 학습률을 정하는 효과적 기술로 학습률 감소(learning rate decay)가 있다. 이는 학습을 진행하면서 학습률을 점차 줄여가는 방식이다. 학습률을 서서히 낮추는 가장 간단한 방법은 매개변수 '전체'의 학습률 값을 일괄적으로 낮추는 것이다. 이를 더욱 발전시킨 것이 AdaGrad이다. AdaGrad는 '각각의' 매개변수에 '맞춤형' 값을 만들어 준다!
AdaGrad는 개별 매개변수에 적응적으로(adaptive) 학습률을 조정하면서 학습을 진행한다. AdaGrad의 갱신 방법은 수식으로는 다음과 같다.
마찬가지로 W는 갱신할 가중치 매개변수, dL/dW는 W에 대한 손실 함수의 기울기,η는 학습률이다. 여기에서는 새로 h라는 변수가 등장한다. h는 위 식에서 보듯 기존 기울기 값을 제곱하여 계속 더해준다(동그라미 기호는 행렬의 원소별 곱셈을 의미한다). 그리고 매개변수를 갱신할 때 1/sqrt(h)를 곱해 학습률을 조정한다. 매개변수의 원소 중에서 많이 움직인(크게 갱신괸) 원소는 학습률이 낮아진다는 뜻인데, 다시 말해 학습률 감소가 매개변수의 원소마다 다르게 적용됨을 뜻한다.
AdaGrad는 과거의 기울기를 제곱하여 계속 더해간다. 그래서 학습을 진행할수록 갱신 강도가 약해진다. 실제로 무한히 계속 학습한다면 어느 순간 갱신량이 0이 되어 전혀 갱신되지 않게 된다. 이 문제를 개선한 기법으로서 RMSProp이라는 방법이 있다. RMSProp은 과거의 모든 기울기를 균일하게 더해가는 것이 아니라, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영한다. 이를 지수이동평균(Exponential Moving Average, EMA)라고 하여, 과거 기울기의 반영 규모를 기하급수적으로 감소시킨다.
2-5. Adadelta
2-6. RMSprop
2-7. Adam
3. Regularization
- Generalization이 잘되도록 규제를 거는 것(학습을 방해하는 것, 테스트데이터에도 잘 적용되도록)
3-1. Early stopping
- 학습을 조기에 종료하는 것
- loss를 보고 loss가 커지는 시점부터 종료하는 것
3-2. Parameter Norm Penalty
- 함수의 공간 속에서 함수를 최대한 부드러운 함수로 보기 위함
3-3. Data Augmentation
- More data are always welcomed
- 주어진 데이터에 변형을 가해 데이터셋의 크기를 늘리는 것(label이 바뀌지 않는 한도내에세 변형)
3-4. Noise Robustness
- Add random noises inputs or weights
3-5. Label Smoothing
- Mixup, Cutout, Cutmix
- 레이블을 깎아서(스무딩) 모델 일반화 성능을 꾀함
- 성능이 올라가는 이유는 불분명, 작동 원리 등에 대해서는 거의 밝혀진 바가 없음
3-6. Dropout
- in each forward pass, randomly set some neurons to zero
3-7 Batch Normalization
- 배치 정규화를 설명하기에 앞서서 gradient descent 방법에 대하여 한번 생각해 보도록 하겠습니다.
- 먼저 위와 같이 일반적인 gradient descent에서는 gradient를 한번 업데이트 하기 위하여 모든 학습 데이터를 사용합니다
- 즉, 학습 데이터 전부를 넣어서 gradient를 다 구하고 그 모든 gradient를 평균해서 한번에 모델 업데이트를 합니다.
- 이런 방식으로 하면 대용량의 데이터를 한번에 처리하지 못하기 때문에 데이터를batch단위로 나눠서 학습을 하는 방법을 사용하는 것이 일반적입니다.
- 그래서 사용하는 것이 stochastic gradient descent 방법입니다.
- SGD에서는 gradient를 한번 업데이트 하기 위하여일부의 데이터만을 사용합니다. 즉,batchsize 만큼만 사용하는 것이지요.
- 위 gradient descent의 식을 보면∑∑에j=Bij=Bi가 있는데BB가batch의 크기가 됩니다.
- 한 번 업데이트 하는 데BB개의 데이터를 사용하였기 때문에 평균을 낼 때에도BB로 나누어 주고 있습니다.
batch normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도각 배치별로 평균과 분산을 이용해 정규화하는 것을 뜻합니다.
위 그림을 보면 batch 단위나 layer에 따라서 입력 값의 분포가 모두 다르지만 정규화를 통하여 분포를 zero mean gaussian 형태로 만듭니다.
그러면 평균은 0, 표준 편차는 1로 데이터의 분포를 조정할 수 있습니다.
여기서 중요한 것은 Batch Normalization은 학습 단계와 추론 단계에서 조금 다르게 적용되어야 합니다.